

















主题赛事
返回
第八届中国研究生创"芯"大赛华为企业命题
发布时间:2025-03-06
来源:中国研究生创“芯”大赛
阅读次数:17578

华为企业介绍
华为创立于1987年,是全球领先的ICT(信息与通信)基础设施和智能终端提供商。我们的20.7万员工遍及170多个国家和地区,为全球30多亿人口提供服务。 华为致力于把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界:让无处不在的联接,成为人人平等的权利,成为智能世界的前提和基础;为世界提供多样性算力,让云无处不在,让智能无所不及;所有的行业和组织,因强大的数字平台而变得敏捷、高效、生机勃勃;通过AI重新定义体验,让消费者在家居、出行、办公、影音娱乐、运动健康等全场景获得极致的个性化智慧体验。
华为企业命题说明
华为企业命题专项奖专门用于奖励选择华为企业命题的赛队,华为企业命题专项奖是初赛奖,由企业专家评出。入围决赛的参赛队伍继续参加大赛决赛奖项评比,与初赛奖项互不冲突。
华为赛题分为通用题和专用题两类,2、3、7 题为通用题,1、4、5、6、8、9、10 题为专用题。评选特等奖时,同等条件下选择专用题的赛队优先。
华为赛题专项奖设置:
特等奖 3队,每队奖金5万元;
一等奖 10队,每队奖金1万元;
二等奖 20队,每队奖金0.5万元。
华为-创芯大赛人才招聘政策:
华为公司鼓励部门从创芯大赛获奖学生中挖掘人才,并在招聘中提供quickpass政策。参加创芯大赛的获奖学生,投递芯片类岗位:
获全国二等奖三等奖学生,可以免机考。
获一等奖及以上学生,免机考和一轮专业面试。
华为专项奖等级等同全国奖对应等级待遇。
赛题一:高线性度时钟相位插值器设计
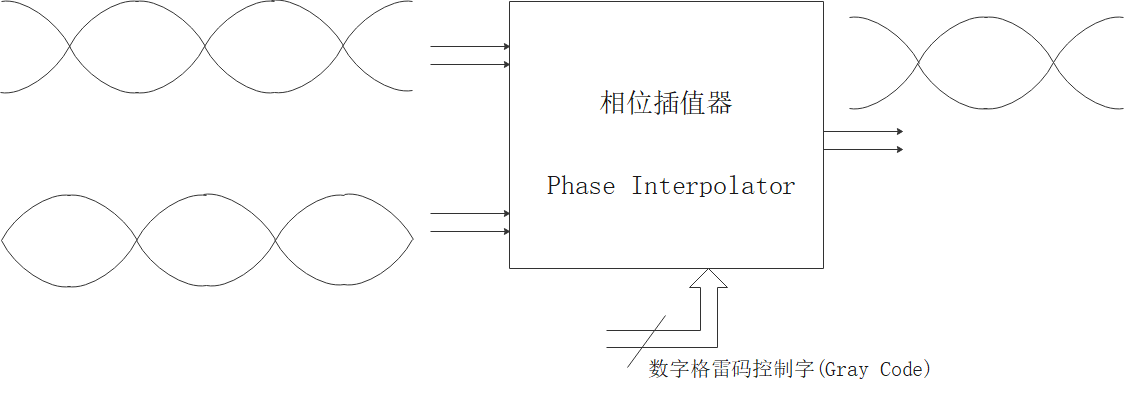
相位插值器(phase interpolator),又称为相位旋转器(phase rotator),是一类对时钟相位进行大范围细颗粒度调节的电路单元,应用于高速接口等模拟IP当中。
典型的相位插值器,输入是两对正交的差分时钟,输出两相差分时钟,输出在数字控制字的控制下,调节输出时钟的相位。如下图所示:
请按照如下约束进行设计:
|
参数项 |
取值范围 |
说明 |
|
输入约束与输出负载 |
||
|
输入正弦信号频率范围 |
3GHz ~ 9GHz |
要求电路在3GHz到9GHz频率范围内都可以满足要求。 |
|
输入正弦信号摆幅 |
单端300mVpp |
|
|
输入控制字位宽 |
8bit |
8bit控制字对应256个控制档位,每个档位平均调节1.41°,8bit控制字可实现输出时钟相位360°调节。 |
|
输入RJ(Random Jitter,随机抖动) |
50fsRMS |
输入时钟上带有50fsRMS的随机抖动(RJ),相位噪声谱可以按照白噪声进行仿真 |
|
输入控制字编码格式 |
格雷码 |
|
|
输入控制字刷新频率 |
1GHz |
|
|
输入控制字变化步长 |
+/- 1步 |
每次输入控制字可以不变、增加1个code或者减小1个code; |
|
输出驱动负载电容 |
25fF |
输出的一对差分时钟的每个pin上带有25fF负载电容 |
|
输出指标约束 |
||
|
输出信号摆幅 |
> 单端250mVpp |
|
|
输出相位INL (积分非线性) |
< +/- 1.25° |
INL曲线定义为:实际的 控制字-输出相位特性曲线 与 理想的 控制字-输出相位特性曲线的差;这里要求INL曲线最大值小于1.25°,最小值大于-1.25°(INL peak to peak 小于2.5°); |
|
输出相位DNL (微分非线性) |
< +/- 0.7° |
DNL定义为 实际的 控制字-输出相位特性曲线的步长与理想步长(1.41°)之间的差值 |
|
输出RJ(Random Jitter,随机抖动) |
<100fsRMS |
|
|
输出相位切换毛刺 |
< +/- 1.5° |
数字控制字切换过程中,输出相位可能会出现突变,相位突变值不超过 +/- 1.5° |
|
其他约束 |
||
|
工艺 |
标准CMOS工艺,建议28nm或更先进工艺节点。 |
|
|
功耗 at 9GHz输入 |
<6mW |
|
|
结温范围 |
0°C至105°C |
|
|
电源电压 |
可根据工艺自己选择合适电压域 |
|
|
电源电压变化范围 |
+/-5% |
|
|
Corner |
至少覆盖TT、FF、SS、SF、FS 5个corner |
|
评审得分点:
- 有完整的电路原理图、版图及前后仿结果。
- 在满足输出摆幅和功耗约束的条件下, RJ、INL、DNL、切换毛刺等输出指标的仿真结果绝对值越小,得分越高。
- 版图中长信号走线、电感、电容等关心Q值的部分需要采用电磁仿真抽取。
- 需要提供PVT仿真结果。
- 需要有设计文档,文档中要体现具体设计思路(如电路指标分析分解、架构选取、关键指标的设计分析、core管类型及尺寸的选取依据、匹配网络的设计考虑、版图寄生的影响等)。
- 版图布局合理,面积紧凑。
- 查询业界典型产品或paper的指标,分析差距存在的原因,和可能的改进方向。
输出要求:
- 详细的设计说明文档。
- 电路版图。
- 电路原理图及仿真TB(testbench)设置说明。
专家答疑邮箱:
zhouqinyu@hisilicon.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116166579032342528
赛题二:ICS电路设计(无线终端)
规格描述及要求:
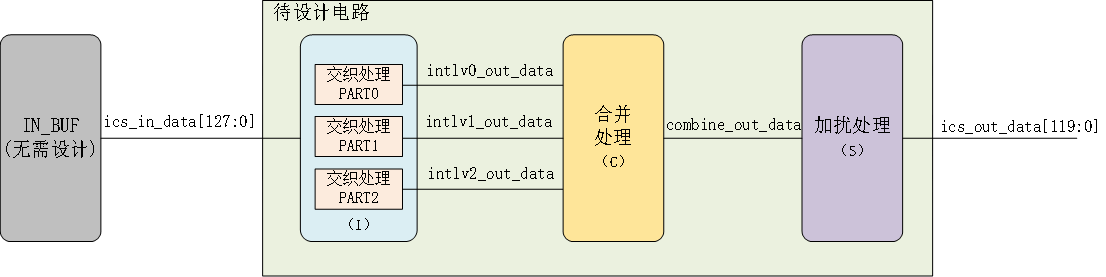
图1.模块示意图
本考题为设计一个电路完成三路bit数据的交织(interleave)、合并(combine)和加扰(scramble)处理。如上图所示,交织处理通过同一组接口,从外部IN_BUF(外部模块,无需开发)分时读取三路长度为N0/N1/N2 bit的待交织数据,分别进行交织处理后的bit数据长度为E0/E1/E2。IN_BUF读接口支持每cycle读取连续128bit待交织数据。三路交织处理后的bit数据并不是所有bit都有效,有效bit数据起始点为S0/S1/S2,有效bit数据长度为L0/L1/L2,总有效bit数据长度LL = L0 + L1 + L2。取三路交织处理后的有效bit按照特定规则合并成一路的过程即为合并处理。加扰处理过程为对合并处理后的输出bit数据和特定随机序列进行按位异或。最后将加扰处理后的bit数据按照特定规则拼接成120bit对外输出。上图仅为示意图,完成功能前提下,具体内部实现和接口划分没有约束。
详细描述:
IN_BUF数据存放格式:
待交织bit数据在IN_BUF中都按照从低bit到高bit,从低地址到高地址顺序存放;PART0/PART1/PART2三路待交织bit数据分别存放于IN_BUF地址段0~7、8~15和16~23;具体存放顺序如下图所示:
|
PART2 |
H23 |
{bit1023, |
bit1022, |
…, |
bit897, |
bit896} |
|
H22 |
{bit895, |
bit894, |
…, |
bit769, |
bit768} |
|
|
H21 |
{bit767, |
bit766, |
…, |
bit641, |
bit640} |
|
|
H20 |
{bit639, |
bit638, |
…, |
bit513, |
bit512} |
|
|
H19 |
{bit511, |
bit510, |
…, |
bit385, |
bit384} |
|
|
H18 |
{bit383, |
bit382, |
…, |
bit257, |
bit256} |
|
|
H17 |
{bit255, |
bit254, |
…, |
bit129, |
bit128} |
|
|
H16 |
{bit127, |
bit126, |
…, |
bit1, |
bit0 } |
|
|
PART1 |
H15 |
{bit1023, |
bit1022, |
…, |
bit897, |
bit896} |
|
H14 |
{bit895, |
bit894, |
…, |
bit769, |
bit768} |
|
|
H13 |
{bit767, |
bit766, |
…, |
bit641, |
bit640} |
|
|
H12 |
{bit639, |
bit638, |
…, |
bit513, |
bit512} |
|
|
H11 |
{bit511, |
bit510, |
…, |
bit385, |
bit384} |
|
|
H10 |
{bit383, |
bit382, |
…, |
bit257, |
bit256} |
|
|
H9 |
{bit255, |
bit254, |
…, |
bit129, |
bit128} |
|
|
H8 |
{bit127, |
bit126, |
…, |
bit1, |
bit0 } |
|
|
PART0 |
H7 |
{bit1023, |
bit1022, |
…, |
bit897, |
bit896} |
|
H6 |
{bit895, |
bit894, |
…, |
bit769, |
bit768} |
|
|
H5 |
{bit767, |
bit766, |
…, |
bit641, |
bit640} |
|
|
H4 |
{bit639, |
bit638, |
…, |
bit513, |
bit512} |
|
|
H3 |
{bit511, |
bit510, |
…, |
bit385, |
bit384} |
|
|
H2 |
{bit383, |
bit382, |
…, |
bit257, |
bit256} |
|
|
H1 |
{bit255, |
bit254, |
…, |
bit129, |
bit128} |
|
|
H0 |
{bit127, |
bit126, |
…, |
bit1, |
bit0 } |
交织处理:
PART0/PART1/PART2三路交织处理各自独立,但处理流程完全相同,具体交织处理流程如下4步:
- 从外部读取N bit待加扰bit数据{A0,A1,…,AN-1},循环重复到E bit,得到序列{A0,A1,…,AN-1,A0,A1,…,AN-1,A0,A1,…,Ax},其中E值为交织后的bit数据长度;
- 找到一个边长为P的等腰直角三角形,使得P*(P+1)/2 >=E,(P-1)*P/2<E;
- 将循环重复后的E bit数据按行从左到右从上到下的顺序放入三角形;
- 按列从上到下从左到右的顺序,从首个有效bit数据位置S开始连续输出L bit数据。
以N=32,E=80,S=11,L=68为例,根据上述公式得到P=13,交织处理后的bit数据摆放图如下,最后按照A14,A26,A5,A15,A24,A0,A7,A13,A2,A15,…,A10,A23,A3,A11的顺序输出。
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
11 |
12 |
13 |
|
1 |
A0 |
A1 |
A2 |
A3 |
A4 |
A5 |
A6 |
A7 |
A8 |
A9 |
A10 |
A11 |
A12 |
|
2 |
A13 |
A14 |
A15 |
A16 |
A17 |
A18 |
A19 |
A20 |
A21 |
A22 |
A23 |
A24 |
|
|
3 |
A25 |
A26 |
A27 |
A28 |
A29 |
A30 |
A31 |
A0 |
A1 |
A2 |
A3 |
|
|
|
4 |
A4 |
A5 |
A6 |
A7 |
A8 |
A9 |
A10 |
A11 |
A12 |
A13 |
|
|
|
|
5 |
A14 |
A15 |
A16 |
A17 |
A18 |
A19 |
A20 |
A21 |
A22 |
|
|
|
|
|
6 |
A23 |
A24 |
A25 |
A26 |
A27 |
A28 |
A29 |
A30 |
|
|
|
|
|
|
7 |
A31 |
A0 |
A1 |
A2 |
A3 |
A4 |
A5 |
|
|
|
|
|
|
|
8 |
A6 |
A7 |
A8 |
A9 |
A10 |
A11 |
|
|
|
|
|
|
|
|
9 |
A12 |
A13 |
A14 |
A15 |
|
|
|
|
|
|
|
|
|
|
10 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
11 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
12 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
13 |
|
|
|
|
|
|
|
|
|
|
|
|
|
交织处理有以下约束:
- PART0/PART1/PART2三路不一定都有效,但至少有一路有效;
- PART0/PART1/PART2三路交织处理的N/E/S/L参数值不一定相同;
- 待交织处理的bit数据长度N的取值集合为{32,64,128,256,512,1024},共6种取值;
- 交织处理后bit数据长度E和输入bit数据长度N满足,E >= N且E <= 8192;
- 交织处理后的bit数据长度E,有效bit数据起点S和bit长度L满足,L % Q = 0,L+S-1 <= E,L >=1;其中Q为合并处理模块参数,表示连续Qbit数据为一个整体进行合并处理,取值集合为{1,2,4,6,8,10},共6种取值;
合并处理:
合并处理过程即是将所有有效PART的有效bit数据,按照一定的规则摆放成LL/Q行,每行摆放10bit数据,其中低Qbit摆放有效bit数据,其余位置全部摆放0。有效bit数据从低bit到高bit,从低行数到高行数顺序摆放,最终按照行数从小到大的顺序输出。合并处理bit数据摆放存在优先级,具体优先级为PART0>PART1>PART2。
对于PARTX(X的取值范围为0/1/2)摆放规则为,剔除比PARTX优先级高的PART已经占用的行,从剩余行中的第0行开始,固定每间隔![]() 行,占用一行用来摆放PARTX的bit数据,直到PARTX的有效bit数据摆完为止。其中,Lx为PARTX有效bit数据长度,Lt为LL剔除优先级大于PARTX的所有有效PART的有效bit数据长度之和。
行,占用一行用来摆放PARTX的bit数据,直到PARTX的有效bit数据摆完为止。其中,Lx为PARTX有效bit数据长度,Lt为LL剔除优先级大于PARTX的所有有效PART的有效bit数据长度之和。
以Q = 8,L0 = 32,L1 = 48,L2 = 80为例,总有效bit数据长度LL = L0 + L1 + L2=160;
-
- Part0:Lt = LL = 160,
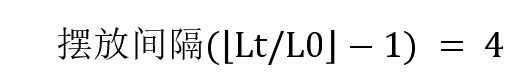 ;
; - Part1:Lt = LL - L0 = 128,
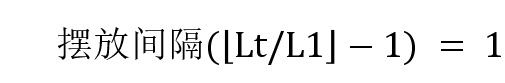 ;
; - Part2:Lt = LL - L0 - L1= 80,
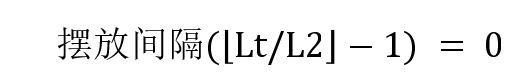 。
。
- Part0:Lt = LL = 160,
假设PART0交织处理后的有效bit数据为X0,X1,…X31;PART1交织处理后的有效bit数据为Y0,Y1,…Y47;PART2交织处理后的有效bit数据为Z0,Z1,…Z79,三路bit数据合并处理后的bit数据如下图所示,最终按照行H0 -> H1 -> … -> H19输出给后级。
|
H19 |
{0, |
0, |
Z79, |
Z78, |
Z77, |
Z76, |
Z75, |
Z74, |
Z73, |
Z72} |
|
H18 |
{0, |
0, |
Z71, |
Z70, |
Z69, |
Z68, |
Z67, |
Z66, |
Z65, |
Z64} |
|
H17 |
{0, |
0, |
Z63, |
Z62, |
Z61, |
Z60, |
Z59, |
Z58, |
Z57, |
Z56} |
|
H16 |
{0, |
0, |
Z55, |
Z54, |
Z53, |
Z52, |
Z51, |
Z50, |
Z49, |
Z48} |
|
H15 |
{0, |
0, |
X31, |
X30, |
X29, |
X28, |
X27, |
X26, |
X25, |
X24} |
|
H14 |
{0, |
0, |
Z47, |
Z46, |
Z45, |
Z44, |
Z43, |
Z42, |
Z41, |
Z40} |
|
H13 |
{0, |
0, |
Y47, |
Y46, |
Y45, |
Y44, |
Y43, |
Y42, |
Y41, |
Y40} |
|
H12 |
{0, |
0, |
Z39, |
Z38, |
Z37, |
Z36, |
Z35, |
Z34, |
Z33, |
Z32} |
|
H11 |
{0, |
0, |
Y39, |
Y38, |
Y37, |
Y36, |
Y35, |
Y34, |
Y33, |
Y32} |
|
H10 |
{0, |
0, |
X23, |
X22, |
X21, |
X20, |
X19, |
X18, |
X17, |
X16} |
|
H9 |
{0, |
0, |
Z31, |
Z30, |
Z29, |
Z28, |
Z27, |
Z26, |
Z25, |
Z24} |
|
H8 |
{0, |
0, |
Y31, |
Y30, |
Y29, |
Y28, |
Y27, |
Y26, |
Y25, |
Y24} |
|
H7 |
{0, |
0, |
Z23, |
Z22, |
Z21, |
Z20, |
Z19, |
Z18, |
Z17, |
Z16} |
|
H6 |
{0, |
0, |
Y23, |
Y22, |
Y21, |
Y20, |
Y19, |
Y18, |
Y17, |
Y16} |
|
H5 |
{0, |
0, |
X15, |
X14, |
X13, |
X12, |
X11, |
X10, |
X9, |
X8 } |
|
H4 |
{0, |
0, |
Z15, |
Z14, |
Z13, |
Z12, |
Z11, |
Z10, |
Z9, |
Z8 } |
|
H3 |
{0, |
0, |
Y15, |
Y14, |
Y13, |
Y12, |
Y11, |
Y10, |
Y9, |
Y8 } |
|
H2 |
{0, |
0, |
Z7, |
Z6, |
Z5, |
Z4, |
Z3, |
Z2, |
Z1, |
Z0 } |
|
H1 |
{0, |
0, |
Y7, |
Y6, |
Y5, |
Y4, |
Y3, |
Y2, |
Y1, |
Y0 } |
|
H0 |
{0, |
0, |
X7, |
X6, |
X5, |
X4, |
X3, |
X2, |
X1, |
X0 } |
加扰处理:
将合并处理后的有效bit数据(每行仅低Qbit数据有效)和随机序列进行按bit异或处理的过程即为加扰处理。具体的扰码发生器![]() 的生成公式为:
的生成公式为:

加扰处理后的数据每连续12行为一组,按照行数从小到大的顺序拼接成120bit的数据,不足12行时不足部分用零补充,最后再按照组数从小到大的顺序输出。由于不是每次输出12行都有效,因此还需要输出有效行数指示,表示当前12行输出数据中有多少行是有效数据,取值范围为1~12。
以合并处理章节示例中输出数据为例,假设扰码序列编号为C0,C1,…,C159,…。如下图所示,经过加扰处理后的输出数据为D0 = {H11,H10,...,H1,H0}和D1 = {H23,H22,...,H13,H12},对应的有效行数分别为12和8,最终输出时按照组数从小到大的顺序先输出D0后输出D1。
|
D1={ |
H23 |
{0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0 } |
|
H22 |
{0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0 } |
|
|
H21 |
{0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0 } |
|
|
H20 |
{0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0, |
0 } |
|
|
H19 |
{0, |
0, |
Z79^C159, |
Z78^C158, |
Z77^C157, |
Z76^C156, |
Z75^C155, |
Z74^C154, |
Z73^C153, |
Z72^C152} |
|
|
H18 |
{0, |
0, |
Z71^C151, |
Z70^C150, |
Z69^C149, |
Z68^C148, |
Z67^C147, |
Z66^C146, |
Z65^C145, |
Z64^C144} |
|
|
H17 |
{0, |
0, |
Z63^C143, |
Z62^C142, |
Z61^C141, |
Z60^C140, |
Z59^C139, |
Z58^C138, |
Z57^C137, |
Z56^C136} |
|
|
H16 |
{0, |
0, |
Z55^C135, |
Z54^C134, |
Z53^C133, |
Z52^C132, |
Z51^C131, |
Z50^C130, |
Z49^C129, |
Z48^C128} |
|
|
H15 |
{0, |
0, |
X31^C127, |
X30^C126, |
X29^C125, |
X28^C124, |
X27^C123, |
X26^C122, |
X25^C121, |
X24^C120} |
|
|
H14 |
{0, |
0, |
Z47^C119, |
Z46^C118, |
Z45^C117, |
Z44^C116, |
Z43^C115, |
Z42^C114, |
Z41^C113, |
Z40^C112} |
|
|
H13 |
{0, |
0, |
Y47^C111, |
Y46^C110, |
Y45^C109, |
Y44^C108, |
Y43^C107, |
Y42^C106, |
Y41^C105, |
Y40^C104} |
|
|
H12 |
{0, |
0, |
Z39^C103, |
Z38^C102, |
Z37^C101, |
Z36^C100, |
Z35^C99, |
Z34^C98, |
Z33^C97, |
Z32^C96 } |
|
|
D0={ |
H11 |
{0, |
0, |
Y39^C95, |
Y38^C94, |
Y37^C93, |
Y36^C92, |
Y35^C91, |
Y34^C90, |
Y33^C89, |
Y32^C88 } |
|
H10 |
{0, |
0, |
X23^C87, |
X22^C86, |
X21^C85, |
X20^C84, |
X19^C83, |
X18^C82, |
X17^C81, |
X16^C80 } |
|
|
H9 |
{0, |
0, |
Z31^C79, |
Z30^C78, |
Z29^C77, |
Z28^C76, |
Z27^C75, |
Z26^C74, |
Z25^C73, |
Z24^C72 } |
|
|
H8 |
{0, |
0, |
Y31^C71, |
Y30^C70, |
Y29^C69, |
Y28^C68, |
Y27^C67, |
Y26^C66, |
Y25^C65, |
Y24^C64 } |
|
|
H7 |
{0, |
0, |
Z23^C63, |
Z22^C62, |
Z21^C61, |
Z20^C60, |
Z19^C59, |
Z18^C58, |
Z17^C57, |
Z16^C56 } |
|
|
H6 |
{0, |
0, |
Y23^C55, |
Y22^C54, |
Y21^C53, |
Y20^C52, |
Y19^C51, |
Y18^C50, |
Y17^C49, |
Y16^C48 } |
|
|
H5 |
{0, |
0, |
X15^C47, |
X14^C46, |
X13^C45, |
X12^C44, |
X11^C43, |
X10^C42, |
X9^C41, |
X8^C40 } |
|
|
H4 |
{0, |
0, |
Z15^C39, |
Z14^C38, |
Z13^C37, |
Z12^C36, |
Z11^C35, |
Z10^C34, |
Z9^C33, |
Z8^C32 } |
|
|
H3 |
{0, |
0, |
Y15^C31, |
Y14^C30, |
Y13^C29, |
Y12^C28, |
Y11^C27, |
Y10^C26, |
Y9^C25, |
Y8^C24 } |
|
|
H2 |
{0, |
0, |
Z7^C23, |
Z6^C22, |
Z5^C21, |
Z4^C20, |
Z3^C19, |
Z2^C18, |
Z1^C17, |
Z0^C16 } |
|
|
H1 |
{0, |
0, |
Y7^C15, |
Y6^C14, |
Y5^C13, |
Y4^C12, |
Y3^C11, |
Y2^C10, |
Y1^C9, |
Y0^C8 } |
|
|
H0 |
{0, |
0, |
X7^C7, |
X6^C6, |
X5^C5, |
X4^C4, |
X3^C3, |
X2^C2, |
X1^C1, |
X0^C0 } |
接口信号:
|
信号名称 |
I/O |
位宽 |
描述 |
|
clk |
I |
1 |
时钟,频率为450MHz |
|
rst_n |
I |
1 |
异步复位,同步撤离信号,0表示复位,1表示解复位 |
|
ics_start |
I |
1 |
启动信号,单时钟周期脉冲信号 |
|
ics_c_init |
I |
31 |
随机序列 |
|
ics_q_size |
I |
4 |
bit数据合并处理基本单元,对应上文中的参数Q |
|
ics_part0_en |
I |
1 |
part0使能,1表示part0有效,0表示part0无效 |
|
ics_part0_n_size |
I |
11 |
part0待交织数据bit长度,对应上文中的参数N0 |
|
ics_part0_e_size |
I |
14 |
part0交织处理后所有数据bit长度,对应上文中的参数E0 |
|
ics_part0_l_size |
I |
14 |
part0交织处理后的有效bit数据长度,对应上文中的参数L0 |
|
ics_part0_st_idx |
I |
14 |
part0交织处理后的有效bit数据起始点,对应上文中的参数S0 |
|
ics_part1_en |
I |
1 |
part1使能,1表示part1有效,0表示part1无效 |
|
ics_part1_n_size |
I |
11 |
part1待交织数据bit长度,对应上文中的参数N1 |
|
ics_part1_e_size |
I |
14 |
part1交织处理后所有数据bit长度,对应上文中的参数E1 |
|
ics_part1_l_size |
I |
14 |
part1交织处理后的有效bit数据长度,对应上文中的参数L1 |
|
ics_part1_st_idx |
I |
14 |
part1交织处理后的有效bit数据起始点,对应上文中的参数S1 |
|
ics_part2_en |
I |
1 |
part2使能,1表示part2有效,0表示part2无效 |
|
ics_part2_n_size |
I |
11 |
part2待交织数据bit长度,对应上文中的参数N2 |
|
ics_part2_e_size |
I |
14 |
part2交织处理后所有数据bit长度,对应上文中的参数E2 |
|
ics_part2_l_size |
I |
14 |
part2交织处理后的有效bit数据长度,对应上文中的参数L2 |
|
ics_part2_st_idx |
I |
14 |
part2交织处理后的有效bit数据起始点,对应上文中的参数S2 |
|
ics_rd_en |
O |
1 |
待交织处理bit数据读使能 |
|
ics_rd_addr |
O |
5 |
待交织处理bit数据读地址 |
|
ics_rd_data |
I |
128 |
待交织处理bit数据读数据,读使能的下一拍有效 |
|
ics_out_sof |
O |
1 |
第一个输出数据标志,和第一个有效数据ics_out_vld对齐 |
|
ics_out_eof |
O |
1 |
最后一个输出数据标志,和最后一个有效数据ics_out_vld对齐 |
|
ics_out_vld |
O |
1 |
输出数据有效标志,1表示有效输出数据有效 |
|
ics_out_num |
O |
4 |
交织处理输出12行数据中有效行数指示,取值范围为1~12; |
|
ics_out_data |
O |
120 |
交织、合并、加扰处理完后的输出数据,每次输出120bit |
接口时序
以三个PART都有效场景为例,对外接口时序如下图所示:
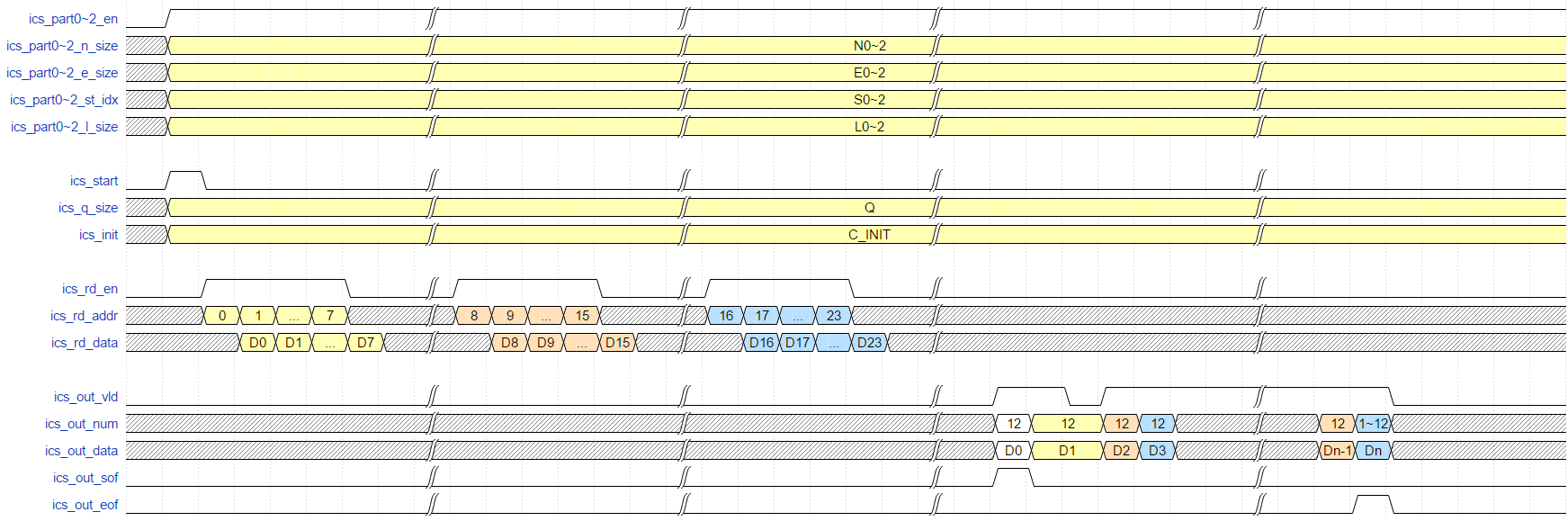
接口信号时序约束:
- 静态配置参数需要在start当拍到ics_out_eof之间(含ics_out_eof当拍)保持不变;
- 读使能的下一拍返回待交织bit数据,每拍返回连续128个bit;
- 数据输出的同时输出数据有效标志vld、首个数据指示sof和最后一个数据指示eof;
- 首个数据指示sof时序同第一个有效数据vld,最后一个数据指示eof时序同最后一个有效数据vld;
- 首个数据指示sof和最后一个数据指示eof任何场景下需要满足成对出现;
- 输入信号不要求reg_in(寄存器打拍后使用),输出信号要求reg_out(寄存器输出);
- 不支持上一轮未完成即启动新一轮处理,支持最快eof下一拍启动新一轮处理;
- 处理时延(从ics_start到ics_out_eof之间的间隔)要求不超过2500个时钟cycle;
评审得分点:
- 设计方案文档描述清晰,模块功能划分合理;
- 实现功能正确,满足题目要求;
- 文档包含对模块功耗、面积和处理时延优化的措施说明;
- 功耗、面积和处理时延指标以所有参赛团队在各个专项的归一化分数统计,以各专项第一名的指标为10分,最后一名为1分,其他名次指标在中间做线性量化分数。
- 总分=0.1*功耗分 + 0.3*面积分 + 0.6*时延分;
- 要求有较完备的验证方案和验证用例;
输出要求:
- 详细的设计文档和RTL代码;
- 验证环境、验证用例、典型场景验证数据和波形截图;
- 提供面积(推荐使用TSMC 7nm工艺,DC下评估面积)、典型场景功耗和典型场景处理时延评估数据,使用工艺库评估的需标明工艺库,使用FPGA工具评估的,需写明工具版本、device型号、资源占用、时序信息等。
典型场景:
- 提供几种典型场景的参数和数据供调试和处理时延评估,具体见插件。

专家答疑邮箱:
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116168723554811904
赛题三:查表保序管理模块设计
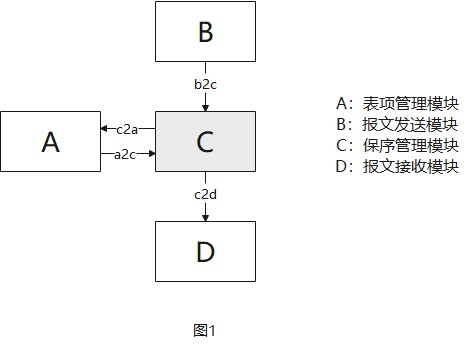
模块功能描述:
- 如图1所示,模块C为考查模块,请完成该模块的方案和编码。它与A/B/D模块有功能交互,模块B为报文发送模块,模块A为表项管理模块,模块D为报文接收模块;
- B模块发送报文给C时,携带查表信息和保序信息,完成查表和满足保序要求后,报文由C发送至D;
- 查表携带的信息lkp_info相同时,A模块返回的查表lkp_rslt相同;
- 每个报文与它前面128个报文的lkp_info相同的概率是50%;
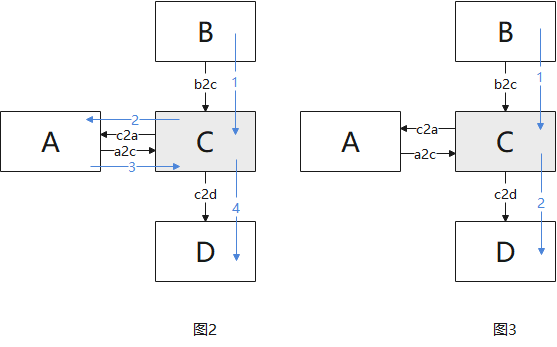
- 如图2所示,需查表报文(lkp_en==1),模块C要拿到lkp_rslt后,报文才可由C发送至D模块;如图3所示,无需查表报文(lkp_en==0),报文可直接由C发送至D模块;
- C模块向A模块发出的查表请求,最大支持256个outstanding。A模块向C模块返回的查表结果,支持乱序返回。
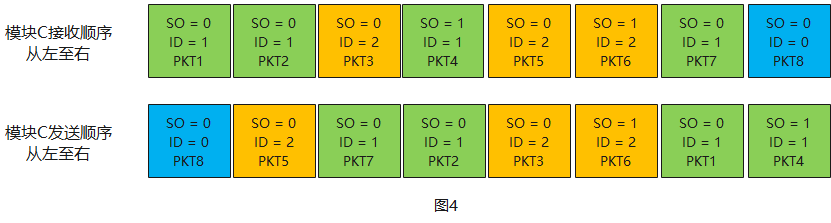
- 保序要求:图4为保序示例。
- Order_id为0,无任何保序要求,此时SO固定为0;
- Order_id非0,有保序要求;
- SO为0的报文,无保序要求;
- SO为1的报文,同Order_id保序,即某个SO为1报文需要等先于它到达C模块的所有相同Order_id报文全部发送到D模块后,才能发送至D模块;
- 同一Order_id,两个SO为1的报文中间SO==0的报文个数最多16个;
模块性能要求:
- 工作频率1GHz;
- 如下三种典型性能场景:
场景一:所有报文无需查表无需保序,即lkp_en为 0,Order_id为全0场景,带宽能达到64GB/s;
场景二:所有报文需要查表,查表延时10~200ns内随机(10~25ns 90%,25~100ns占7%,100~200ns占3%),Order_id取值0~7比例均匀,SO为0和1的报文比例占比80%和20%,带宽尽可能打满;
场景三:报文Order_id取值0~7比例均匀,SO为0和1的报文比例分别占比20%和80%,报文lkp_en取值为0和1的比例分别占比20%和80%,查表延时固定200ns,带宽尽可能打满;
- 性能牵引:
无保序报文尽可能不受到阻塞;
不同Order_id的报文不相互阻塞;
性能尽可能平稳,不出现急剧跳水;
- 在满足模块性能的前提下,尽可能优化模块面积和功耗;
模块接口描述:
|
信号名 |
位宽 |
描述 |
|
时钟复位 |
||
|
clk |
1 |
时钟 |
|
rst_n |
1 |
复位,低电平有效 |
|
B与C模块之间接口信号 |
||
|
b2c_pkt_vld |
1 |
报文有效指示信号,高电平有效 |
|
b2c_pkt_lkp_en |
1 |
报文是否需要查表指示信号 1:报文需要查表 0:报文不需要查表 |
|
b2c_pkt_lkp_info |
20 |
报文查表边带信息 |
|
b2c_pkt_odr_id |
3 |
报文保序队列ID,取值范围0~7 注:值为0时,表示无保序要求,此时对应so固定为0。 |
|
b2c_pkt_so |
1 |
报文强保序标记 0:无保序要求; 1:发送顺序要保证在同Order_id前面接收的报文已完成发送 |
|
b2c_pkd_payload |
512 |
报文数据 |
|
c2b_pkt_rdy |
1 |
C模块可接受报文状态指示 当b2c_pkt_vld & c2b_pkt_rdy为1时,表示报文被C模块接收。 |
|
A与C模块之间接口信号 |
||
|
c2a_lkp_vld |
1 |
查表请求有效指示信号,高电平有效 |
|
c2a_lkp_info |
20 |
查表边带信息,来自于报文接收时b2c_pkt_lkp_info |
|
c2a_lkp_req_id |
10 |
查表请求ID |
|
a2c_lkp_rdy |
1 |
A模块可接受查表请求状态指示 当c2a_lkp_vld & a2c_lkp_rdy为1时,表示查表请求被A模块接收。 |
|
A与C模块之间接口信号 |
||
|
a2c_lkp_rsp_vld |
1 |
查表响应有效指示信号,C模块须无条件接收查表响应,高电平有效 |
|
a2c_lkp_rsp_id |
10 |
查表响应ID,用于指示是哪个c2a_lkp_req_id相对应的结果 |
|
a2c_lkp_rslt |
20 |
查表响应结果,需随报文发至模块D |
|
D与C模块之间接口信号 |
||
|
c2d_pkt_vld |
1 |
报文有效指示信号,高电平有效 |
|
c2d_pkt_odr_id |
3 |
保序队列ID,取值范围0~7 |
|
c2d_pkt_so |
1 |
强保序标记 |
|
c2d_pkt_lkp_rslt |
20 |
报文查表结果 |
|
c2d_pkt_payload |
512 |
报文数据,C模块不改变数据内容 |
|
d2c_pkt_rdy |
1 |
D模块可接受报文状态指示 当c2d_pkt_vld & d2c_pkt_rdy为1时,表示报文被D模块接收。 |
评审得分点:
- 实现功能正确,满足题目要求;
- 文档分(占10%):模块功能划分合理,微架构方案描述清晰,包含性能及资源分析,面积和功耗优化方案说明;
- 性能分(占70%):三个性能场景,场景一占20%,场景二占40%,场景三占40%;各场景总分10分为例,以最高带宽为满分,带宽每减少1%,减少1分。
- 面积分(占20%):所有参赛团队在各个专项的归一化分数统计;
- 要求有完备的验证方案,验证用例和验证报告;
输出要求:
- 模块C的详细设计文档和RTL代码;
- 模块C的验证环境、验证用例、验证数据和波形截图,验证报告;
- 模块C的性能测试报告,包含三种性能场景中性能数据说明;
- 模块面积数据,使用工艺库评估的需标明工艺库,推荐使用TSMC 12nm工艺,DC下评估面积;
专家答疑邮箱:
guojian111@hisilicon.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116174987567480832
赛题四:3D 芯片设计:True 3D Macro Placement + Partition
描述及要求:
- 基于题目中提供的 Netlist 和 3DPDK Mempool,实现具有网表划分功能的 3D Placement。
- 完成True Macro Placement,优化线长。
- 进行密度评估: Overflow低于 10%。
- 上下层芯片的利用率差异控制在 5% 以内。
- 局部 3D 互联密度(Density)满足要求,(x um Pitch 条件)达标。
- 加分项:时序优化(Timing)。
- 加分项:拥塞优化(Congestion)。

点击图标下载3DPDK Mempool或打开链接下载:cpipc.acge.org.cn/sysFile/downFile.do?fileId=760ce6e234314bcea6b8e40c00cc3563
评审得分点:
- 实现算法功能正确,满足题目要求;
- 设计方案文档描述清晰,模块功能划分合理;
- 线长部分占 40%,Density Overflow 部分占40%;Timing 10%,Congestion10%
- 要求有完备的验证方案和验证用例;
输出要求:
- 算法设计与优化分析报告;(含方案分析与Placement 线长报告,Timing报告,Density Map)
- Placement Iteration 线长,Density Overflow,3D 互联数量的变化;
- 提供Placement功耗、性能、面积评估数据,使用工艺库评估的需标明工艺库;使用FPGA工具评估的,需写明工具版本、device型号、资源占用、时序信息等。
专家答疑邮箱:
liuzhe@hisilicon.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116175995349680128
赛题五:NAND2环振优化设计
描述及要求:
高阶环振设计和验证是检验工艺和器件能力的常用方法。要求在限制设备和工艺能力前提下,以NAND2为基准单元,设计功耗-性能-面积最佳的环振。
- 假定现有工艺最低CGP=60nm (contacted gate pitch)的条件,进行器件结构设计,包含N和P型MOSFET各一个。其他材料限制和要求见附件。【20分】
- 进行器件性能仿真与优化,实现最大的开态电流和最小的寄生电容;要求半定量说明为何无法进一步优化的原因。限制关键性能指标符合附件所列指标,其中迁移率需要与参考资料验证。【20分】
- 对器件仿真结果进行建模拟合,要求尽可能缩小附录所列电性指标相对误差,解释所用模型的合理性。【20分】
- 使用前述N和P型MOSFET搭建NAND2单元,进行寄生抽取,要求设计规则不超过ASAP5和IRDS-2021-“5nm”节点所列工艺和设备能力。要求给出版图,包含尺寸和叠层信息。【20分】
- 使用前述NAND2,优化连线搭建97环振,在0.5-1V范围内仿真功耗和性能,给出最优结果。【20分】
评审得分点:
- 晶体管器件搭建包含核心部件和尺寸说明,包含工艺流程示意图及其仿真。
- 给出迁移率验证数据、电性曲线和关键参数提取结果;解释无法进一步优化的分析说明。
- 模型说明、拟合误差。
- NAND2单元版图、设计规则和寄生抽取结果。
- 仿真文件、功耗性能结果、连线版图。
额外说明:
- 上述各题均以所有参赛团队在各个专项的归一化分数统计,以各专项第一名的指标为满分,最后一名的指标为满分的十分之一,其他名次指标在中间做线性量化分数。
- 未做说明的假定,参考ASAP5(Microelectronics Journal 126 (2022) 105481)和IRDS-2021-More Moore-“5”nm;允许自行引入额外的必要假定,但需简述其合理性和必要性。
- 任何一题有给出超越业内理解的新思路,并有效证明可行性,得分可以翻倍。
- 其它说明参见附录:

点击图标下载附录或打开链接下载:cpipc.acge.org.cn/sysFile/downFile.do?fileId=8513d093ff4b4b57934e0846daf3d7cc
输出要求:
- 答案的核心描述和最终数据;
- 模型和参数,使用的仿真软件及其代码,参数提取代码;
- 器件3D结构图、器件module target spec定义、迁移率符合约束的验证曲线、器件TCAD和建模电性数据曲线、环振性能-功耗曲线;
- (如有)额外引用的数据来源。
专家答疑邮箱:
zhangqiang241@hisilicon.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116185270318972928
赛题六:Path-Based Timing Driven Global Placement(后端设计)
描述及要求:
- 题目背景:布局布线工具是VLSI芯片设计中最关键的工具之一。随着工艺的持续演进、DTCO、STCO的持续引入,布局布线面临了由新工艺特性带来的巨大挑战,例如如何在更多的工艺约束下面实现更优的PPA。Global Placement是PnR核心流程的第一步,一定程度上决定了芯片PPA上限。在Global Placement阶段处理好Timing的约束,既能提升Global Placement阶段Timing结果,还能减少PnR过程中的迭代次数。
- 题目价值:当前学术界主流Timing Driven Global Placement方案主要是(1)Net-based、 Pin-based Net Weighting方案(Ref.[1])(2)Differentiable-Timing-Driven Global Placement方案(Ref.[2]),实现的时序结果WNS、TNS均有较大提升空间。
实现Path-Based Timing Driven Global Placement不仅能提升Global Placement环节时序结果,还能提升PnR工具环节间的一致性,从而提升PnR工具整体PPA竞争力。
- 基础平台:
(1)Placer,考虑工作量建议采用开源DreamPlace(DreamPlace 4.0)平台,github地址:https://github.com/limbo018/DREAMPlace。
(2)Timer,考虑工作量建议采用开源OpenTimer,github地址:https://github.com/OpenTimer/OpenTimer。
- 用例:为了便于同前沿学术成果对比,Benchmark Suite采用:ICCAD-2015 CAD contest in incremental timing-driven placement and benchmark suite(Ref.[3])。
评审得分点:
- 实现算法功能正确,满足题目要求,跑通全部用例;
- 算法文档明确说明Global Placement与STA集成方式,要求显式提供解决不同Timing Path时序违例问题的方案;
- 关键指标:
(1)WNS,权重30%。
(2)Top 100关键路径平均WNS,权重20%。
(3)TNS,权重30%。
(4)Runtime,权重10%。
(5)Peak Memory,权重10%。
- 要求跑通ICCAD-2015 CAD contest benchmark suite全部用例,且report关键指标,并和DreamPlace 4.0结果对比。按照上述5个指标打分,加权后满分100。其中WNS、TNS、WNS100优化减半或更多得100分,以此类推,持平及以下0分。Runtime、Peak Memory按照胜负打分,胜100,败0分。
输出要求:
- 算法设计方案;
- Benchmark全部用例运行环境、log、时序报告等;
- 结果分析报告。
关键引用
- P. Liao, S. Liu, Z. Chen, W. Lv, Y. Lin and B. Yu, "DREAMPlace 4.0: Timing-driven global placement with momentum-based net weighting", Proc. DATE, pp. 939-944, 2022.
- Z. Guo and Y. Lin, "Differentiable-timing-driven global placement", Proceedings of the IEEE/ACM Design Automation Conference, pp. 1315-1320, 2022.
- M C Kim, J Hu, J Li et al., "ICCAD-2015 CAD contest in incremental timing-driven placement and benchmark suite [C]", 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), pp. 921-926, 2015.
专家答疑邮箱:
zhangrui727@huawei.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116186584994201600
赛题七:高速高线性度DAC设计
描述及要求:
1. 输入信号带宽:10M~500M
2. DAC 采样率:Fs>=4GHz
3. SFDR 要求:SFDR在100M下,SFDR>78dBc,SFDR在500M下SFDR>66dbc。幅度为-6dBFs~
-15dBFs,需要MC下的最差线性度
4. 功耗:<40mW
5. 输入信号幅度:1Vpp FullScale
6. 架构:不限,Current Steering DAC优选,同时需要设计TIA
7. 工艺:建议使用标准CMOS工艺
8. 温度范围:−20℃至+85℃
9. 供电电压:随选定工艺而定
评审得分点:
1.思路正确,根据性能、功耗的要求要有合理的架构选型分析;
2.设计Current Steering DAC的架构,需要设计TIA,性能看TIA输出,TIA架构分析的完备性和性能分析作为加分项;
3.在满足指标要求的情况下FOM越高,得分越高。线性度越高得分越高;
4.需要有文档,说明各个子电路性能指标的分解依据,子电路结构的选择依据等;
5.各个子模块的功耗、噪声和非线性等用饼状图给出占比分析;
6.校准算法选择及有效性分析,或者是DEM选择是需要包含的。分析的是否详细作为加分项;
7.查询业界典型产品和paper的指标,分析差距存在的原因,和可能的改进方向;
输出要求:
- 详细设计报告:内容包含但不限于系统框图、系统&子模块工作原理分析、子模块指标分解和电路原理图;
- 仿真报告:内容需包含子模块及整系统的仿真条件、仿真电路、仿真波形及仿真结果分析,仿真波形包括但不限于DC/AC/TRAN/MC;详细的前后仿真结果;
- 电路原理图、版图及仿真电路数据库;
专家答疑邮箱:
fankai1@huawei.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116187344226140160
赛题八:VCSEL激光器的3D Vectorial求解
赛题涉及的VCSEL结构请见以下文献:
https://ieeexplore.ieee.org/document/970909
描述及要求:
- 采用文献中的benchmark structure结构,求解VCSEL(Vertical-cavity surface-emitting laser)的resonance效应和光场分布;
- 需通过Vectorial的Maxwell方程求解3D的VCSEL结构;
- 与文献中的结果进行对比。
评审得分点:
- 功能正确实现;
- 理论分析越全面,得分越高;
- 越快速算法,得分越高;
- 算量越低但不影响精准度,得分越高;
- 收敛性越好,得分越高。
输出要求:
- 所采用的方法及其数学推导;
- 详细设计文档和算法模型代码;
- 给出方法的计算量和计算时间;
- 与文献结果的对比。
专家答疑邮箱:
zhaochong1@huawei.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116168979398967296
赛题九:POLAR码编解码模块设计
描述及要求:
- 基于提供的极化码可靠度序列设计POLAR码编解码模块POLAR_ENC/POLAR_DEC;
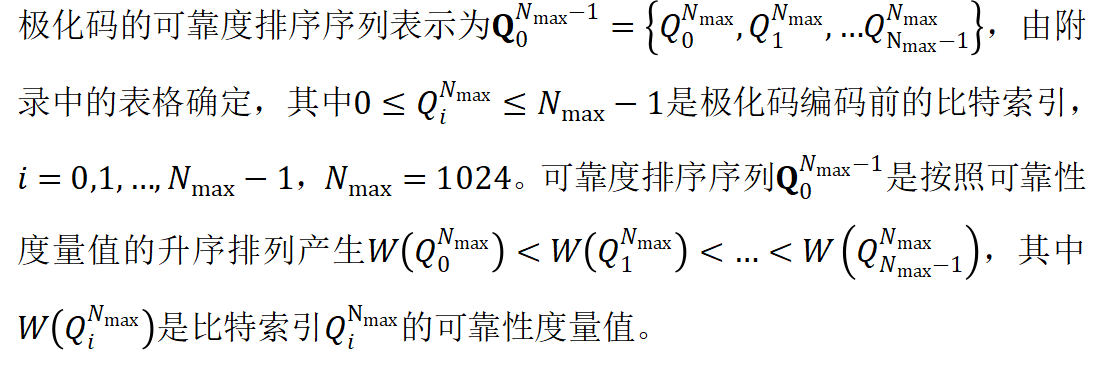
- 码块大小固定为1024bit,码率支持1/4和3/8两种码率。
N:码长,固定为1024比特
K:信息比特长度
R:码率,R=K/N,即1/4码率时K=256,3/8码率时K=384
- 极化码可靠度序列见表格

- 通过编码IP完成编码后,参赛者使用标准BPSK调制、加噪、解调生成5bit LLR译码数据,通过解码IP进行解码;
- 分析信噪比SNR与误帧率PER之间的关系,以1000帧随机码字为标准,PER从10%下降到0.1%时,SNR上升不超过2.4dB;
- 设计、优化定点算法,使用verilog实现该POLAR_ENC/POLAR_DEC模块;
- 在64MHz时钟主频下,吞吐率不低于32Mbps。
需要满足以下延时要求:
a)编码延时小于1.5us
b)延时小于7.5us
- 相同SNR性能、编解码延迟的情况下,追求面积功耗优化;
- 模块接口信号列表如下:
|
POLAR_ENC |
|||
|
Signal Name |
I/O |
Width |
Description |
|
clk |
I |
1 |
输入时钟(64MHz) |
|
rst_n |
I |
1 |
异步复位 |
|
polar_rate_sel |
I |
1 |
polar码率指示:0表示1/4码率,1表示3/8码率 |
|
polar_enc_start |
I |
1 |
编码启动脉冲信号 |
|
polar_enc_data_in |
I |
384 |
编码前比特序列,1/4码率时低256比特有效 |
|
polar_enc_done |
O |
1 |
编码完成脉冲信号 |
|
polar_enc_data_out |
O |
1024 |
编码后数据 |
|
POLAR_DEC |
|||
|
Signal Name |
I/O |
Width |
Description |
|
clk |
I |
1 |
输入时钟(64MHz) |
|
rst_n |
I |
1 |
异步复位 |
|
polar_rate_sel |
I |
1 |
polar码率指示:0表示1/4码率,1表示3/8码率 |
|
polar_dec_start |
I |
1 |
译码启动脉冲信号 |
|
llr_data |
I |
1024*5 |
按顺序解调得到的LLR,每个LLR为经过对称饱和限幅的5bit有符号数 |
|
polar_dec_data_vld |
O |
1 |
译码输出数据有效 |
|
polar_dec_data_out |
O |
8 |
译码后数据,以字节为单位顺序输出 |
|
polar_dec_done |
O |
1 |
译码完成脉冲信号 |
评审得分点:
- 实现算法功能正确,满足题目要求;
- 设计方案文档描述清晰,模块功能划分合理;
- 算法文档明确说明模块内部量化定标,及对应的性能分析;
- 编码IP分数占30%,解码IP分数占70%;
- 信噪比SNR与误帧率PER、编解码延迟约束情况下,模块面积越小,功耗越低,得分越高;
- PPA指标均以所有参赛团队在各个专项的归一化分数统计,以各专项第一名的指标为10分,最后一名的指标为1分,其他名次指标在中间做线性量化分数。
- 要求有完备的验证方案和验证用例;
输出要求:
- 算法设计与优化分析报告;(含方案分析与性能仿真结果)
- POLAR_ENC/POLAR_DEC详细设计文档和RTL代码;
- POLAR_ENC/POLAR_DEC验证环境、验证用例、验证数据和波形截图;
- 提供IP的功耗、性能、面积评估数据,使用工艺库评估的需标明工艺库;使用FPGA工具评估的,需写明工具版本、device型号、资源占用、时序信息等。
专家答疑邮箱:
niuchuan@huawei.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116188978142429184
赛题十:单反馈架构下的宽带ET功放的建模算法与线性化系统设计
赛题描述:
包络跟踪(ET, Envelope Tracking)是通过发送信号实时包络对射频功率放大器的直流供电进行调制,进而最大化射频功放效率的一种射频前端子系统。由于其较强的性能优势与灵活性,在无线移动终端领域被广泛应用。同时也因为较大的商业价值,一直以来都是海思、高通、MTK等主要终端芯片厂商的竞争重地。
Part 1: 宽带ET-PA建模
ET系统的设计难度,随着系统带宽的增加显著变大。最重要的原因是,宽带ET电源调制工作在大带宽模式下会不可避免的产生非理想因素,并受到PA输出低频分量的泄露影响,进一步污染其供电波形的质量。这种供电波形与宽带功放的失真将会协同影响宽带ET功放的非线性行为,恶化发射信号的各项指标。
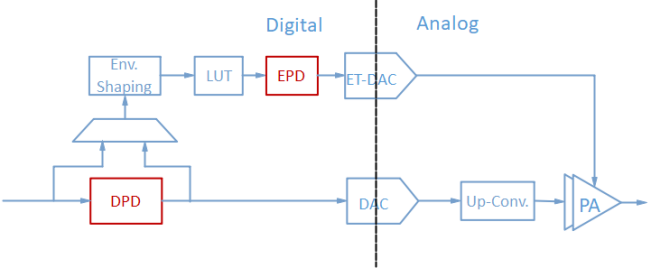
为宽带ET-PA设计线性化方案,如数字预失真系统(DPD),除了考虑功放自身的数学建模外,还需要考虑对ETM的行为,才有可能达到较理想的模型精度。
Part 2: 线性化方案构思
基于所提供的建模方案,给出对应的线性化方案原型。
具体要求:
- 命题人员提供(1)基带时域信号;(2)对应的ETM输入信号;(3)PA的输出测量信号(波形数据下载链接:https://share.weiyun.com/8lZ1hZiF)。
- 要求利用(1)~(3),构建非线性模型,完成对PA测量输出的回归建模。
- 给出基于该模型的线性化方案线性构思。
注意
- 如使用AI方法完成任务,需要对所使用的网络结构进行白盒化的数学描述;
专家答疑邮箱:
qianjing3@huawei.com
赛题互动交流答疑社区链接:https://www.chaspark.com/#/races/competitions/1116190184713666560

