

















主题赛事
返回
飞腾企业命题-第九届中国研究生创“芯”大赛
发布时间:2026-01-30
来源:中国研究生创“芯”大赛
阅读次数:5927

飞腾企业命题说明
飞腾企业命题专项奖系针对初赛阶段设立的独立奖项,旨在表彰选择并攻关飞腾命题的优秀团队。该奖项由企业技术专家组评审,与大赛决赛奖项评选机制并行。入围决赛的团队将继续角逐大赛总决赛奖项,两类奖项互不冲突,获奖权益可叠加享受。
飞腾企业命题专项奖设置
一等奖3队,每队奖金1万元;
二等奖6队,每队奖金0.5万元。
飞腾创芯大赛人才招聘政策
获全国二等奖、三等奖学生,可以免笔试;
全国一等奖学生,获得HR直通卡,直达专业终面。
飞腾专项奖等级等同全国奖对应等级待遇。
飞腾企业命题交流Q群
1077142513
组队报名及作品提交链接(创芯大赛官网)
https://cpipc.acge.org.cn/cw/hp/10
注:具体报名时间、参赛流程及赛题详情,请以大赛组委会后续发布的正式通知为准。
赛题目录
| 序号 | 题目名称 |
| 赛题一 | 3D芯片中TSV的热应力和机械应力物理建模与可靠性仿真 |
| 赛题二 | AI超分辨率模型高效硬件加速器设计与实现 |
| 赛题三 | 智核融合·低耗强算——基于CPU和NPU的异构处理器设计 |
·鉴于飞腾赛题一(3D芯片中TSV的热应力和机械应力物理建模与可靠性仿真)对创新性要求更高,评选企业专项奖时,同等条件下选择专用题的赛队优先。未能达到赛题基本要求的作品不参与评奖。
·Ctrl+F 输入赛题名,可快速查找。
赛题一:3D芯片中TSV的热应力和机械应力物理建模与可靠性仿真
赛题背景
随着摩尔定律走向停滞,芯片的三维集成成为进一步提升芯片算力的主要途径。然而,对于基于TSV工艺和同质/异质芯粒键合的3D芯片而言,由芯片功率耗散产生热应力和机械应力,并可能导致TSV结构产生损伤,进而影响芯片的功能和寿命。
因此,对基于TSV工艺和同质/异质芯粒键合的3D 芯片而言,需要建立芯片中TSV结构的热-机械应力物理学解析模型,并使用该模型对给定的TSV参数(包括几何尺寸、材料参数、动态运行参数等)对TSV结构的热-机械应力场分布进行仿真分析,以评估对芯片的功能和寿命所产生的影响。
赛题目标
为实现TSV和同质/异质芯粒键合工艺条件下3D芯片的全芯片热-机械应力仿真,课题应当完成以下研究内容:
1.建立参数化的芯片热应力和机械应力物理学解析模型,模型可支持不同工艺参数和芯片功耗特征下的TSV热应力和机械应力仿真;
2.对所提出的热应力物理学解析模型进行算法实现,并对其做并行化优化,以实现TSV结构的热应力仿真模拟器;
3.在芯片动态功耗数据作为输入参数的条件下,分析和研究3D-TSV、键合的热应力时间演化律,并完成算法实现。
出题方为参赛队伍提供:
【TSV结构说明】
https://edu.phytium.com.cn/course/99/task/249/show
【pu_cpm_model】
https://edu.phytium.com.cn/course/99/task/248/show
交付内容及要求
1. 提出参数化的3D-TSV结构的热应力物理学解析模型,要求热应力仿真精度不低于TCAD仿真工具精度的99%以上;
2. 根据所提出的物理学模型,实现3D-TSV芯片的热应力和机械应力仿真模拟器软件,要求:
a) 仿真速度应达到TCAD仿真软件的10倍以上;
b) 支持不同的几何结构参数(如TSV直径/尺寸、晶圆厚度、封装结构)和芯片功耗参数(如芯片功率密度、环境温度)输入;
c) 支持热应力和机械应力时间演化律仿真;
d) 开放源代码,或者提供静态/动态运行时库以及API接口以支持二次开发。
评审要点:
1. 功能实现精准无误,与题目要求高度契合;(10分)
2. 设计方案文档表述清晰,模块功能划分科学合理;(10分)
3. 文档明确阐释模块内部量化指标及相应的性能分析;(20分)
4. 需具备完善的验证方案与验证用例;(20分)
5. 在同等输入参数条件下,模型的运行速度越高、误差越低,所获分数越高;模型的运行速度和误差精度指标均基于所有参赛团队在各专项的归一化分数进行统计,二者权重各占50%,以各专项排名第一者为满分(20分)、最末者为0分(未完成者不计分、不参与排名),中间成绩者以实际运行速度和误差精度按对数关系映射,即:
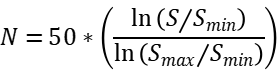
其中S表示各专项的绝对数值,![]() 和
和![]() 代表对应的最大值和最小值。
代表对应的最大值和最小值。
赛题答疑邮箱:
zhangyouzhi1859@phytium.com.cn
赛题二:AI超分辨率模型高效硬件加速器设计与实现
赛题背景
远程办公、在线教育的常态化推动视频会议市场爆发式增长,但弱网环境下的低码率压缩、画面模糊(人脸、共享文档文字失真)、实时性不足等问题,严重制约沟通效率。传统插值算法难以恢复细节,而深度学习超分模型虽效果优异,却因参数量大、计算复杂,在笔记本、平板等端侧设备上面临实时性与功耗的双重压力,难以满足视频会议场景需求。
因此,聚焦视频会议核心痛点,要求设计AI超分硬件加速器:通过模型轻量化与硬件架构创新,在保障超分效果的同时,实现低延迟、低功耗实时处理,破解“高清与实时”矛盾,为远程交互提供优质视觉体验,兼具技术创新性与工程落地性。
赛题目标
面向端侧场景,设计专用的AI超分硬件加速器实现“清晰度-实时性-功耗”之间的平衡,加速器设计约束:
1.AI模型、量化、稀疏化方法不做约束,图像输入格式(RGB or YUV)不限,AI模型可参考CVPR NTIRE相关论文
2.适配会议画面核心特征(人像、文档等),实现实时、高保真的超分辨率输出;
3.基于Xilinx ZC706 FPGA或者资源相当的FPGA,在所提供数据集合上实现x2、x4超分
验证方案在实际视频会议场景下的画质与性能表现。
出题方为参赛队伍提供:
【数据集】https://seungjunnah.github.io/Datasets/reds.html
参赛使用数据集为REDS数据集,关于REDS数据集的介绍详见论文:S. Nah et al., "NTIRE 2019 Challenge on Video Deblurring and Super-Resolution: Dataset and Study"
交付内容及要求
1.提供AI模型结构、训练、量化的说明文档及源代码,以及模型到硬件加速器指令的转换工具
2.提供硬件加速器的详细设计文档
3.提供硬件加速器的源代码,可在Xilinx Vivado工具中进行仿真验证以及综合用于评估资源开销
评审要点:
1.功能实现精准无误,与题目要求高度契合(10);
2.设计方案文档表述清晰,模块功能划分科学合理(10);
3.文档明确阐释模块内部量化指标及相应的性能分析(20);
4.需具备完善的验证方案与验证用例(20);
5.在同等性能约束条件下,模块面积越小、功耗越低,所获分数越高(40,若未通过正确性仿真验证以及生成bitstream,此项得分为0);PPA 指标均基于所有参赛团队在各专项的归一化分数进行统计。
赛题答疑邮箱:
zhangyouzhi1859@phytium.com.cn
赛题三:智核融合·低耗强算——基于CPU和NPU的异构处理器设计
一、背景
随着物联网(IoT)、人工智能(AI)和边缘计算的飞速发展,对于低功耗、高性能异构计算的需求愈发紧迫。传统CPU在处理复杂AI算法时,面临着算力不足和能效比低下的双重难题,而专用NPU(神经网络处理器)虽可高效执行矩阵运算,但缺乏通用控制能力。通常情况下,32位低功耗RISC处理器,凭借其超低能耗和较高运算效率,在智能传感器、可穿戴设备等领域处于主导地位。然而,其单核性能有限,难以满足实时AI推理需求。
在此情形下,32位低功耗RISC处理器 + 32位NPU的异构架构成为解决问题的关键所在:通过AXI总线实现CPU与NPU的高效协同,既保留了32位低功耗RISC处理器的低功耗控制优势,又借助NPU的并行计算能力提升了整体能效。据行业数据显示,采用异构架构的芯片在图像识别任务中,能效比能够提升10倍以上,同时功耗降低60%。
典型应用场景如下:在智能家居领域,门锁具备本地化人脸识别功能(响应时间小于200毫秒);在工业检测领域,可进行缺陷检测(精度不低于99.5%,吞吐量达50帧/秒);在可穿戴设备领域,能实现实时心电图分析(功耗小于10毫瓦,续航能力提升3倍)。
二、目的与意义
目的
1.技术突破:设计一款支持AXI总线(含单拍/Burst传输)的异构处理器,实现CPU与NPU的零拷贝数据交互。
2.能效优化:通过任务划分(CPU处理逻辑控制,NPU执行矩阵运算),降低整体功耗。
意义
1.填补市场空白:当前低功耗AI芯片市场以单核MCU或高功耗APU为主,异构方案稀缺。
2.推动边缘AI普及:在智能家居、工业检测等场景中,实现本地化实时推理,减少云端依赖。
3.技术标准制定:通过AXI总线接口的标准化设计,为行业提供可复用的异构通信协议。
三、设计指标与要求
(一)基础完成指标
1、异构处理器集成
在指定的CPU中设计并集成32位NPU计算单元,采用4×4脉动阵列架构。指定的CPU包括两类:一类是基于Cortex-M0核的CPU;另外一类是基于RISC-V核的CPU。
实现CPU与NPU通过AXI总线(支持单拍传输AXI-Lite和Burst传输AXI)的高效通信。
2、功能验证
完成AXI Burst传输正确性测试(地址递增模式),确保数据传输无误。
实现CPU与NPU的协同任务,如NPU执行矩阵运算,CPU处理逻辑控制。
使用VS Code+iverilog联合仿真平台,覆盖至少95%的代码路径,确保功能正确性。
3、性能测试
RTL仿真频率设定为200MHz,NPU算力达到≥0.5TOPS@INT8(峰值),确保基本AI推理能力。
总线带宽利用率在Burst传输场景下达到≥60%,保证数据传输效率。
4、低功耗设计
实现时钟门控技术,当NPU未使用时关闭脉动阵列时钟,降低静态功耗。
(二)进一步优化指标
1、异构处理器性能优化
NPU算力提升:在基础指标上,进一步优化NPU设计,使其算力尽可能接近或超过1TOPS@INT8(峰值)。
总线带宽利用率提升:通过优化总线架构和仲裁机制,提高总线带宽利用率,目标达到≥80%(Burst传输场景)。
2、硬件加速与扩展性
动态可调脉动阵列:设计动态可调脉动阵列,能够根据任务需求动态调整PE(处理单元)的连接关系,提高阵列的灵活性和计算效率。
互连拓扑结构:采用AXI共享总线互连拓扑结构,提升系统可用带宽,支持更多主设备和从设备的并行访问。
DMA控制器集成:在基础指标上,进一步集成DMA控制器,实现数据的高效搬运,减少CPU参与数据传输的开销。
3、低功耗设计创新
动态频率调整(DFS):实现NPU的动态频率调整功能,根据任务负载动态调整工作频率,进一步降低功耗。
创新低功耗设计:探索并应用其他创新低功耗设计方法,如电源门控、多电压域设计等,以降低整体功耗。
4、生态兼容性与标准化
AXI总线接口标准化:通过AXI总线接口的标准化设计,为行业提供可复用的异构通信协议,促进技术普及和生态发展。
(三)输出要求
- 详细设计文档及RTL代码;
- RTL仿真报告或者FPGA验证报告。
四、验证与测试要求
1、功能验证
完成所有基础功能测试,确保异构处理器的基本功能正确无误;进行压力测试和边界条件测试,验证系统的稳定性和鲁棒性。
(1)基本要求:完成RTL仿真。
(2)加分项:完成FPGA验证。
2、性能测试
使用标准测试集(如MNIST、CIFAR-10等)进行AI推理性能测试,记录推理时间和准确率。
测量并记录总线带宽利用率、NPU算力等关键性能指标。
3、低功耗测试
在不同工作负载下测量系统功耗,验证低功耗设计的有效性。
评估动态频率调整(DFS)等功能对功耗的影响。
五、评分规则
- 功能实现正确,满足题目要求,要求有完备的验证方案和验证用例:
- 实现4×4脉动阵列(20分)或者实现动态可调脉动阵列(25分);
- AXI共享总线互连拓扑结构(5分);
- DMA控制器(5分);
- 低功耗设计(门控时钟、DFS等)(5分);
- 设计方案文档描述清晰,模块功能划分合理(10分);
- 性能指标评分以基础完成指标对应的分数为0分基准,进一步优化指标对应的分数为40分,通过线性化处理计算得分,最高可得50分。
- 完成FPGA验证可加10分。
结语
本方案通过32位低功耗RISC处理器与32位NPU的异构融合,结合AXI总线的高效通信,为低功耗、低成本AI边缘计算提供了可量产的解决方案。项目团队将聚焦能效比优化与生态兼容性,助力客户在万物互连时代抢占技术制高点。
CPU
ARM Cortex-M0 RTL源码下载地址:
https://www.arm.com/resources/free-evaluation-arm-cpus
RISC-V核RTL源码参考下载地址如下(下载/拉取工具为git)
PicoRV32:
https://github.com/YosysHQ/picorv32.git(自带AXI4接口)
Darkriscv:
https://github.com/darklife/darkriscv.git(不带AXI接口,可参考PicoRV32解决)
赛题答疑邮箱:
zhangyouzhi1859@phytium.com.cn
