

















主题赛事
返回
Cadence企业命题-第九届中国研究生创“芯”大赛
发布时间:2026-02-23
来源:中国研究生创“芯”大赛
阅读次数:5

关于cadence
Cadence 是 AI 和数字孪生领域的市场领导者,率先使用计算软件加速从硅片到系统的工程设计创新。我们的设计解决方案基于 Cadence 的 Intelligent System Design™ 战略,可帮助全球领先的半导体和系统公司构建下一代产品(从芯片到全机电系统),服务超大规模计算、移动通信、汽车、航空航天、工业、生命科学和机器人等领域。2024 年,Cadence® 荣登《华尔街日报》评选的“全球最佳管理成效公司 100 强”榜单。Cadence 解决方案提供无限机会。如需了解更多信息,请访问公司网站:www.cadence.com
Cadence命题专项奖
Cadence企业命题专项奖专门用于奖励选择Cadence企业命题的赛队,由企业专家评出。Cadence企业命题专项奖是初赛奖,入围决赛的参赛队伍继续参加大赛决赛奖项评比,与初赛奖项互不冲突。
奖项设置
Cadence企业命题一等奖:1 支队伍,每队奖金 1 万元;
Cadence企业命题二等奖:4 支队伍,每队奖金 5 千元;
Cadence-创芯大赛人才政策
Cadence公司鼓励技术部门从创芯大赛获奖学生中选拔人才。在招聘过程中,获奖学生可直接进入HR面试环节,或通过Cadence实习直通车优先获得实习岗位。 此外,Cadence公司还可为在 Cadence 实习且有志于出国深造的同学提供 Cadence 标准格式的推荐信。
赛题清单
|
序号 |
题目 |
|
赛题一 |
格基后量子密码硬件加速器设计 |
|
赛题二 |
基于大模型推理的FlashAttention高性能硬件加速器IP设计 |
赛题一:格基后量子密码硬件加速器设计
一、 赛题背景
随着量子计算技术的快速发展,传统RSA、ECC等公钥密码算法面临被量子计算机破解的威胁。NIST已于2024年正式发布后量子密码(PQC)标准,其中ML-DSA(FIPS 204,数字签名)和ML-KEM(FIPS 203,密钥封装)作为基于模格的标准算法,成为后量子时代密码学的核心基石。
完整的安全通信系统需要数字签名和密钥封装协同工作:ML-DSA用于身份认证和数据完整性验证,ML-KEM用于建立共享密钥。然而,这些格基算法涉及大量的多项式运算、数论变换(NTT)和大模数运算,软件实现在资源受限的嵌入式设备中性能低下,难以满足实时性要求。硬件加速是解决性能瓶颈的关键技术路径。
本赛题要求参赛者使用Cadence EDA工具设计高性能的PQC硬件加速器,实现ML-DSA全部三种安全级别(ML-DSA-44/65/87)和ML-KEM全部三种安全级别(ML-KEM-512/768/1024)的硬件加速,通过标准AXI4接口与主机系统集成。
二、赛题要求
设计并实现一个高性能的PQC硬件加速器
2.1具体功能要求(必选)
(1)ML-DSA数字签名加速器:
支持ML-DSA全部三种参数集的硬件加速
- ML-DSA-44(NIST Level 2安全级别)
- ML-DSA-65(NIST Level 3安全级别)
- ML-DSA-87(NIST Level 5安全级别)
实现完整的签名生命周期:
- 密钥生成(ML-DSA.KeyGen)
- 签名(ML-DSA.Sign)- 包含拒绝采样机制
- 验证(ML-DSA.Verify)
(2)ML-KEM密钥封装加速器:
支持ML-KEM全部三种参数集的硬件加速
- ML-KEM-512(NIST Level 1安全级别)
- ML-KEM-768(NIST Level 3安全级别)
- ML-KEM-1024(NIST Level 5安全级别)
实现完整的密钥封装生命周期:
- 密钥生成( ML-KEM. KeyGen )
- 封装(ML-KEM.Encaps)- 生成共享密钥和密文
- 解封装(ML-KEM.Decaps)- 从密文恢复共享密钥
(3)AXI总线接口:实现符合AMBA AXI4规范的主机接口
(4)测试验证:提供完整的测试环境和验证程序
(5)功能验证:
采用SystemVerilog+UVM或Python+cocotb验证框架
通过NIST官方PQC KAT测试向量验证算法正确性:
- FIPS 204(ML-DSA-44/65/87)
- FIPS 203(ML-KEM-512/768/1024)
- NIST 提供的 PQC KAT 测试标准和示例文件网址:
PQC 示例文件页面(含 KAT 文件、API 注释等):
Post-Quantum Cryptography: Additional Digital Signature Schemes | CSRC
2.2 性能要求
(1)主频目标:频率越高越好(Genus物理综合报告)
(2)面积约束:总逻辑门数 ≤ 200万门
- RAM利用率:给出详细的RAM资源利用调度使用情况说明
- 包含所有逻辑单元和存储单元(RAM、寄存器等)
- 等效逻辑门按与非门面积计算
- 面积报告需使用Cadence Joules RTL design studio综合后的等效逻辑门个数
(3)ML-DSA性能指标:
- ML-DSA-87为例:KeyGen < 20k周期,Sign(平均)< 150k周期,Verify < 20k周期
(4)ML-KEM性能指标:
- 以ML-KEM-1024为例:KeyGen < 15k周期,Encaps < 15k周期,Decaps < 10k周期
(5)吞吐量:支持连续操作的流水线处理
(6)能效比:提供功耗分析报告
2.3 可选要求
说明:
1. 加分项需在完成基础要求(baseline)后,克隆baseline设计创建新的独立版本进行开发,与baseline分别提交和评估。加分项设计不得影响baseline的功能和性能指标。
2. 以下加分项按推荐优先级排列,不必全部实现,参赛者可根据团队特长选择完成。
|
优先级 |
加分项 |
主要内容 |
|
P0 |
侧信道防护 |
实现抗侧信道攻击的安全措施: - 功耗平衡技术 - 故障注入检测 |
|
P1 |
组合操作优化 |
实现常用的多步骤组合操作加速: - 签名 + 验证链式操作(证书链验证场景) - 多密钥并行处理 - 减少主机-加速器交互次数,提升端到端性能 |
|
P2 |
深度流水线优化 |
实现多级流水线架构提升连续操作吞吐量: - NTT/INTT多级流水线设计 - 多个操作可并行处理(如同时KeyGen和Sign) - 减少连续操作之间的空闲周期 |
|
P3 |
DMA与批量加速 |
实现AXI Master接口和DMA控制器: - 加速器作为AXI主机,主动读写内存 - 支持批量任务自动处理(无需主机循环调用) - 提供任务队列管理,连续处理多个操作 |
推荐组合方案 (可选):
方案A(安全为主):侧信道防护 + 组合操作优化
方案B(实用为主):深度流水线优化 + DMA与批量加速
方案C(全面):侧信道防护 + 组合操作优化 + 深度流水线优化
工具支持:
Cadence 为本次比赛提供专属云服务器,服务器已预装赛事所需的 Cadence EDA 工具及对应工艺库。本次服务器资源充足,可保障每位参赛选手一人一个独立账号。
如需申请使用云服务器,请下载附件表格填写完整后提交,表格下载链接:
https://cpipc.acge.org.cn/sysFile/downFile.do?fileId=40168f675ca64849be72024c9fb94256
赛题二:基于大模型推理的FlashAttention高性能硬件加速器IP设计
一、赛题背景
Transformer 架构已广泛应用于大模型(LLM/VLM)与多模态系统。在典型 Transformer 模型中,计算开销最为显著、同时对存储与带宽最为敏感的关键算子之一为 Scaled Dot-Product Attention(SDPA):
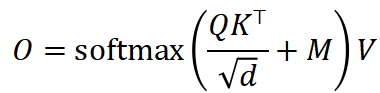
其中 Q , K , V 为Query/Key/Value,D 为每个attention head的维度,M 为mask例如 causal mask)。在朴素实现中,通常需要显式构造![]() (大小约为S×S)及其 softmax 概率矩阵,从而引入如下问题:
(大小约为S×S)及其 softmax 概率矩阵,从而引入如下问题:
- 带宽瓶颈:大量中间张量的读写使得性能受限于外存/显存带宽
- 存储压力:长序列下(约S×S)中间矩阵难以在片上存储
- 端侧落地困难:在功耗与 SRAM 受限的 SoC/加速器上难以高效实现
FlashAttention 系列工作提出了在线(online)softmax + 分块(tiling)+ 融合数据流的实现范式:在不显式存储(约 S×S)注意力矩阵的前提下,完成与 SDPA 等价(或在可控近似误差范围内等价)的计算,从而显著降低带宽压力与中间存储开销。
本赛题要求参赛者使用 Cadence EDA 工具链,设计并实现一个可综合的 FlashAttention-style 注意力算子硬件 IP。参赛设计需在给定张量规模与接口规范下完成端到端注意力计算,并在正确性、性能 (cycles/Fmax)、面积与带宽等维度进行综合评比。
二、赛题要求
参赛团队需要实现一个可综合 RTL IP,支持在指定输入规模下完成 SDPA/FlashAttention-style attention。
2.1 基本功能要求(必选)
(1) 算法定义(SDPA 计算目标)
设序列长度 S ,head 维度 d ,输出维度同 V。对每个query位置 i :
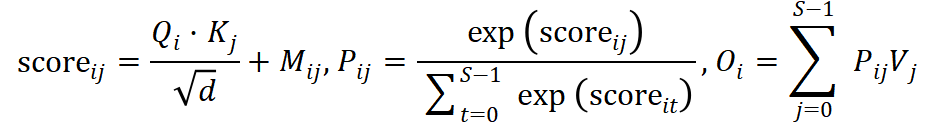
(2) FlashAttention-style 计算约束
必须体现 FlashAttention-style 的关键思想,将据此验收:
- 禁止显式存储注意力矩阵
- 必须使用在线(online)softmax
- 必须分块(tiling)处理 K/V
(3) 固定输入规模
为便于统一测试与比较,Baseline 固定如下规模(单 batch、单 head):
- 序列长度:S = 256
- head 维度:d = 64
- Q/K/V/O 形状:[s,d]
- batch = 1 ,head = 1
(4) 数据格式(定点)
Baseline 统一采用定点格式(便于可综合、低面积/低功耗实现):
- 输入 Q / K / V :Q8.8(16-bit 有符号定点)
- 累加/中间:
- Dot-product 累加:至少 32-bit(建议 40-bit 以上以降低溢出风险)
- softmax 路径:允许使用更高位宽或分段缩放
- 输出 O:Q8.8(16-bit 有符号定点)
(5) 接口要求
Baseline 统一采用"主机配置+加速器 DMA 搬运数据"的模式:
- AXI4-Lite(控制):主机写寄存器(基地址/参数),并通过 CTRL.START 启动、读 STATUS 查询完成。
- AXI4 Master+DMA(数据):加速器启动后用 DMA 从内存读入 Q , K , V, 计算完成后把O 写回内存。
(6) 寄存器
Baseline 固定S = 256,d = 64 。下表仅列出必需寄存器(其余可自行扩展)。
|
Offset |
名称 |
访问 |
说明 |
|
0x00 |
CTRL |
R/W |
bit0:START(写 1 启动) bit1:SOFT_RESET bit2:IRQ_EN |
|
0x04 |
STATUS |
R |
bit0:BUSY bit1:DONE(写 1 清) bit2:ERROR |
|
0x08 |
CFG |
R/W |
bit0:CAUSAL_EN(Baseline 必须支持) bit1:RESERVED |
|
0x14 |
Q_BASE_L |
R/W |
Q 基地址(低 32) |
|
0x18 |
Q_BASE_H |
R/W |
Q 基地址(高 32) |
|
0x1C |
K_BASE_L |
R/W |
K 基地址(低 32) |
|
0x20 |
K_BASE_H |
R/W |
K 基地址(高 32) |
|
0x24 |
V_BASE_L |
R/W |
V 基地址(低 32) |
|
0x28 |
V_BASE_H |
R/W |
V 基地址(高 32) |
|
0x2C |
O_BASE_L |
R/W |
O 基地址(低 32) |
|
0x30 |
O_BASE_H |
R/W |
O 基地址(高32) |
|
0x34 |
STRIDE_BYTES |
R/W |
行 stride(bytes),默认 d*2 |
|
0x38 |
NEG_LARGE |
R/W |
-inf 近似值(Q8.8) |
|
0x3C |
SCALE |
R/W |
|
|
0x40 |
CYCLES |
R |
本次执行周期数 |
(7)存储与资源约束
为体现 FlashAttention-style 的"低中间存储"特性,Baseline 强制约束:
- 禁止存储 score/p 全矩阵
- 片上中间 buffer 限额(不含输入/输出缓存):
允许缓存一小块 K , V tile
允许每行维护 m/l/acc (以及必要流水寄存器)
说明:若参赛者选择把全量 K , V 缓存在片上 SRAM 以减少外存带宽,需在报告中量化带宽收益与 SRAM 代价。
(8)正确性验收
- 单向量对齐(必测)
随机种子生成的 Q , K , V(Q8.8)与 golden 输出。 - 误差门限
与 FP32 golden(同一公式、同一mask)对比:
mean_abs_error (0)≤0.03
max_abs_error (0)≤0.10
若采用不同 exp/倒数近似,需在文档中说明误差来源。
备注:Baseline 使用定点与近似运算,不要求 bit-exact,以误差门限作为验收标准。
(9)测试验证
- 采用 SystemVerilog+UVM 或 Python+cocotb
- 必须包含:
AXI4-Lite 寄存器读写与启动/完成流程
随机 Q , K , V 的端到端验证
Causal mask corner case 验证(如 i = 0行只能看 j = 0 )
2.2 性能要求(必选 Baseline)
(1) 主频目标:频率越高越好(基于 Cadence Genus物理综合报告;鼓励进一步 P&R 收敛)
(2) 面积约束:等效逻辑门数 ≤ 200 万门(含存储器折算,统一用Genus报告的等效逻辑门数,2-input NAND等效口径)
(3) 延迟指标
单次 attention( S = 256,d = 64 , causal)执行周期数<300k cycles
(4) 带宽目标
给出 RD_BYTES/WR_BYTES 统计与优化分析(tile 缓存、复用等)
2.3 可选要求(Bonus 加分项)
说明(重要):
1.所有 Bonus 必须在 Baseline 通过后开展。
2.必须基于 Baseline 重新新建独立项目/独立版本(例如新建目录或新工程),单独开发、单独验证、单独提交。
3.不得修改或影响 Baseline 版本的代码与评估结果(Baseline 仍按原要求独立评测)。
4.所有可选项可以在同一个 Bonus 项目中集中实现;该 Bonus 项目必须基于 Baseline 另行开发,并作为独立版本单独评估(重新仿真/重新综合/重新统计指标)。
|
Item |
加分项 |
主要内容 |
|
1 |
BF16/FP16 版本 |
在相同尺寸下实现 BF16 或 FP16 attention(softmax/exp/倒数硬件化),并给出误差与性能对比 |
|
2 |
多head支持 |
支持 head =4/8 ,接口增加 head 维度与地址/stride 管理 |
|
3 |
更长序列 |
支持 S = 512(或可配置 S ),并保持不存储(约 S×S )中间矩阵 |
|
4 |
Padding mask |
支持输入有效长度L<=S 的 padding mask(对无效 token 置 -inf) |
|
5 |
其他定点格式 |
在Baseline的Q8.8之外,额外支持等价定点格式(如 Q6.10/Q4.12),并给出误差与性能对比 |
|
6 |
Dropout (训练模式) |
在 softmax 后加入 dropout(需明确随机数产生方式与可复现种子) |
|
7 |
更低精度 (INT8/FP8 思路) |
参考 FlashAttention-3 的低精度策略,实现块量化/分块缩放并给出误差收益 |
|
8 |
AXI4-Stream数据接口 |
在 Baseline(AXI4 Master+DMA)之外,额外提供 AXI4-Stream输入/输出接口,便于与其他 IP 级联 |
|
9 |
DMA/任务队列 |
支持多次 attention 连续执行(队列/链式配置),减少主机交互 |
三、工具支持:
Cadence 为本次比赛提供专属云服务器,服务器已预装赛事所需的 Cadence EDA 工具及对应工艺库。本次服务器资源充足,可保障每位参赛选手一人一个独立账号。
如需申请使用云服务器,请下载附件表格填写完整后提交,表格下载链接:
https://cpipc.acge.org.cn/sysFile/downFile.do?fileId=40168f675ca64849be72024c9fb94256
四、提交要求:
参赛队伍需提交主要材料:
代码与设计文件
(1)完整的RTL代码(Verilog/SystemVerilog)
- PQC加速器源代码(ML-DSA + ML-KEM)
- Cadence工具脚本和约束文件(SDC格式)
(2)验证代码
- UVM/cocotb验证环境
- 测试用例和测试向量
- 仿真脚本
(3)Cadence工具生成的报告
- 仿真报告和波形文件
- 物理综合报告(面积、时序、功耗)
报名后会提供提交内容参考模板
