

赛题:大型数字设计实现中关键时序瓶颈的系统分析方法
赛题数据:一个数字运算模块带库的db(居于物理实现)
赛题简介
在大型数字设计的实现(implementation,即综合/P&R)中,因为数据流的复杂交错、先进工艺的多重影响(寄生参数、信号串扰等)以及版图设计合理性和时钟树实现等因素的影响,设计时序报告中的违例并不一定代表着设计里最有挑战的设计瓶颈。在超高速CPU核的实现过程中,最后阶段的关键路径收敛都需要经历一段时间的艰辛细调(一般我们称为timing ECO)。ECO的前期阶段的一般违例可以借助EDA工具进行自动化修复,后期遗留一般是工具自动化很难处理的复杂情况。此时工程师一般按照过往经验做细节的时序分析,然后运用多种技巧多次迭优化的方式达成时序收敛。
本赛题希望可以通过一种比较系统的时序分析办法,在刨除物理设计的影响下追踪并诊断出设计的时序瓶颈。此分析的结论可以在设计实现早期或timing ECO阶段提供加速设计收敛的指引。
本赛题的数据采用了一个已做了初步物理实现(place&route)的富含数据运算特性(通常称data path design)的模块,采用的库为虚拟的32纳米的工艺库。设计的基本信息如下表
|
设计大小 |
~0.16M instance |
|
寄存器总量 |
~8.4K |
|
设计现时钟频率 |
666MHz |
具体要求
第一部分:设计瓶颈分析
本部分所用数据为已完成单元布局(cell placement),时钟延迟为ideal clock。参赛者需要在PT环境下读入本赛题数据,进行时序分析,检查设计里的可进一步优化时序路径,找出设计的理论频率上限。具体可优化的时序路径在此场景下假定为下列几类:
1. 假违例:一个时序路径下的逻辑单元,其delay为设计中其它所有同样单元的delay的平均值的2倍或以上,则该单元的delay可认为不合理,可以被替代为设计中其它所有同样单元的delay的平均值。
逻辑单元的delay的平均值的获取方式:参赛者需在PT读入设计数据,然后用report_paths_of_interest.tcl(数据包里提供的脚本)产生时序报告(paths_of_interest.rpt)。参赛者可以通过tcl、perl或python分析paths_of_interest.rpt,统计出该报告里的cell类型和这些cell类型在此时序报告里的delay平均值。
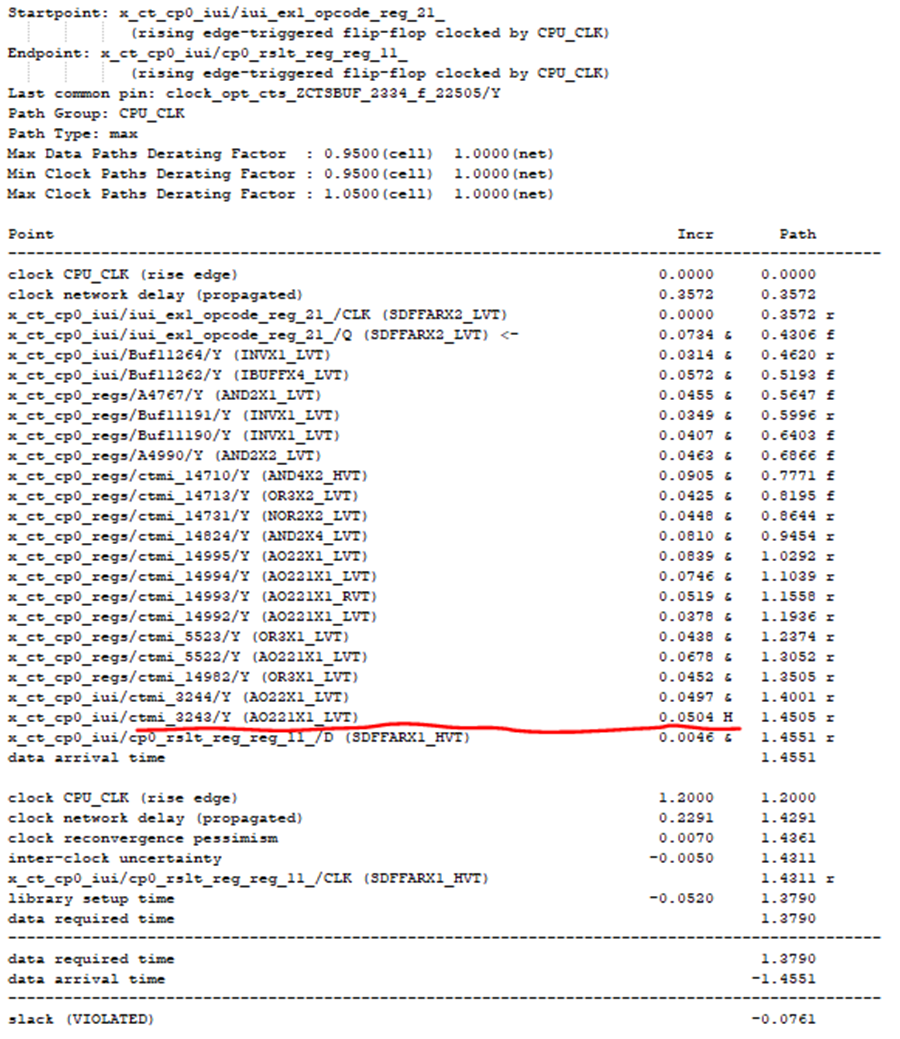
假违例的处理例子如下:假设 参赛者通过统计,得出lib cell AO221X1_LVT在本设计的平均delay为0.0497。而现有一个路径下(时序报告如图1)该cell的delay超出该平均的的2倍(如下例该cell的delay为0.1316)。此时参赛者可以通过set_annotated_delay的方式,把该cell的delay人为设为此lib cell的delay的平均值,作为评估设计合理优化后该cell的delay。此时序路径的通过该处理后违例值由原来的-0.1573缩小为-0.0761(如图2)。
图1
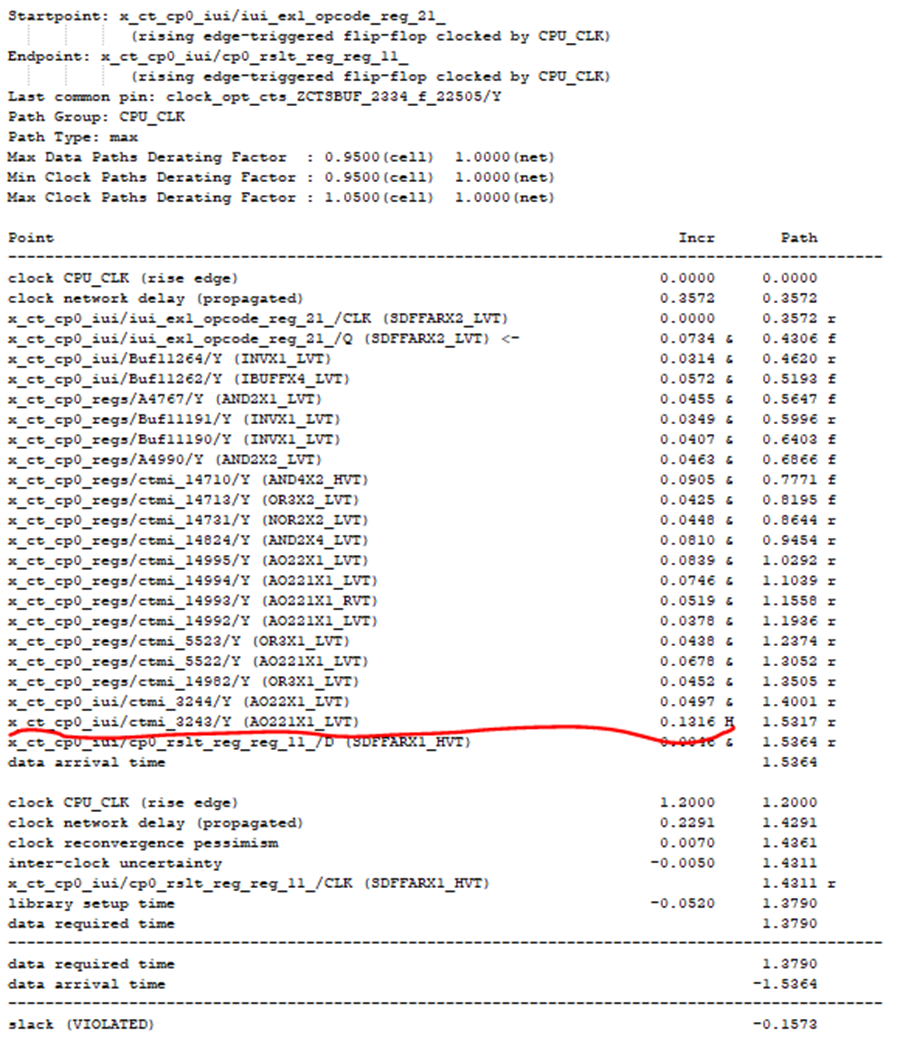
图2
2. 冗余buffer或inverter:时序路径下的冗余buffer或连续成对的inverter归类为可优化逻辑(注:冗余buffer或inverter为去除后设计功能对等且不产生新的设计实现违例如max_fanout)。该buffer或inverter假定为被移除后不引起其它部分的时序变化。例子:如图3所示,假设如下4个buffer
.“x_ct_cp0_regs/clock_opt_opto_gre_mt_inst_269433” “x_ct_cp0_regs/clock_opt_opto_gre_mt_inst_269430” “x_ct_cp0_regs/clock_opt_opto_gre_mt_inst_269422” “x_ct_cp0_regs/clock_opt_opto_gre_mt_inst_269421”
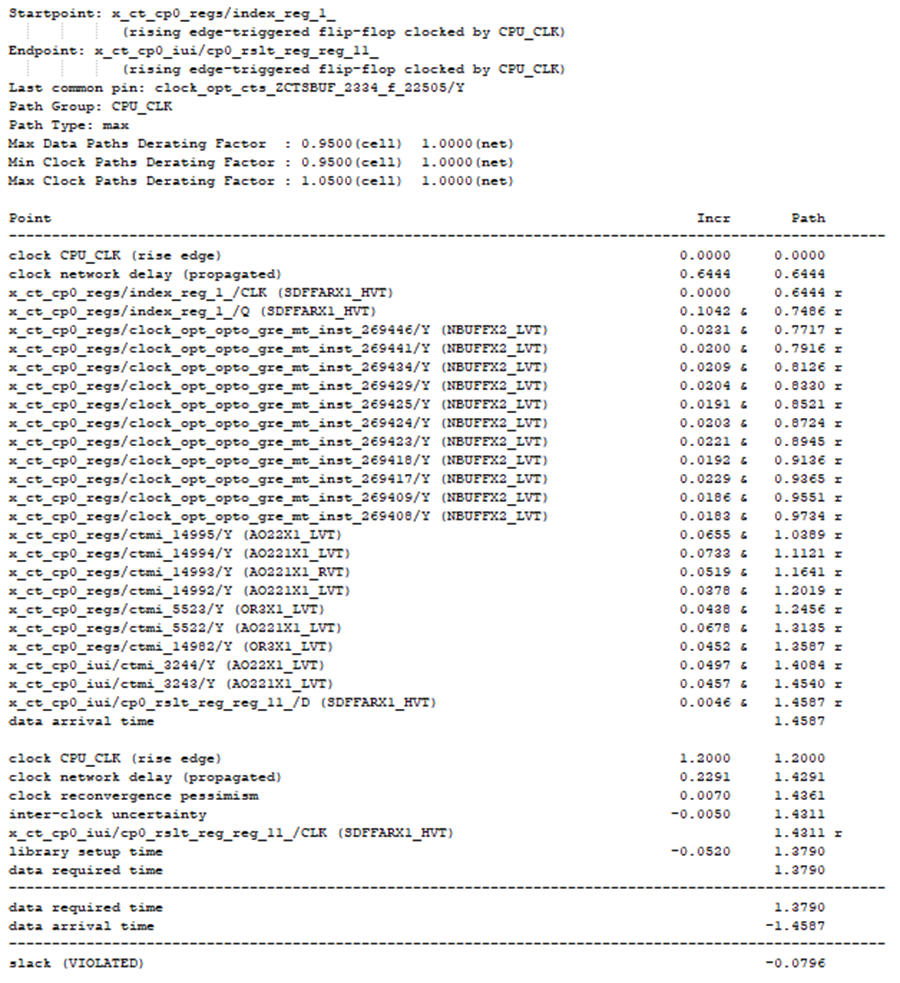
移除后不造设计的max_fanout违例, 那么通过remove_buffer 移除该4个冗余buffer后,可以得到优化后的时序,如图4。设计的违例由原-0.1507缩小为-0.0769。
图3
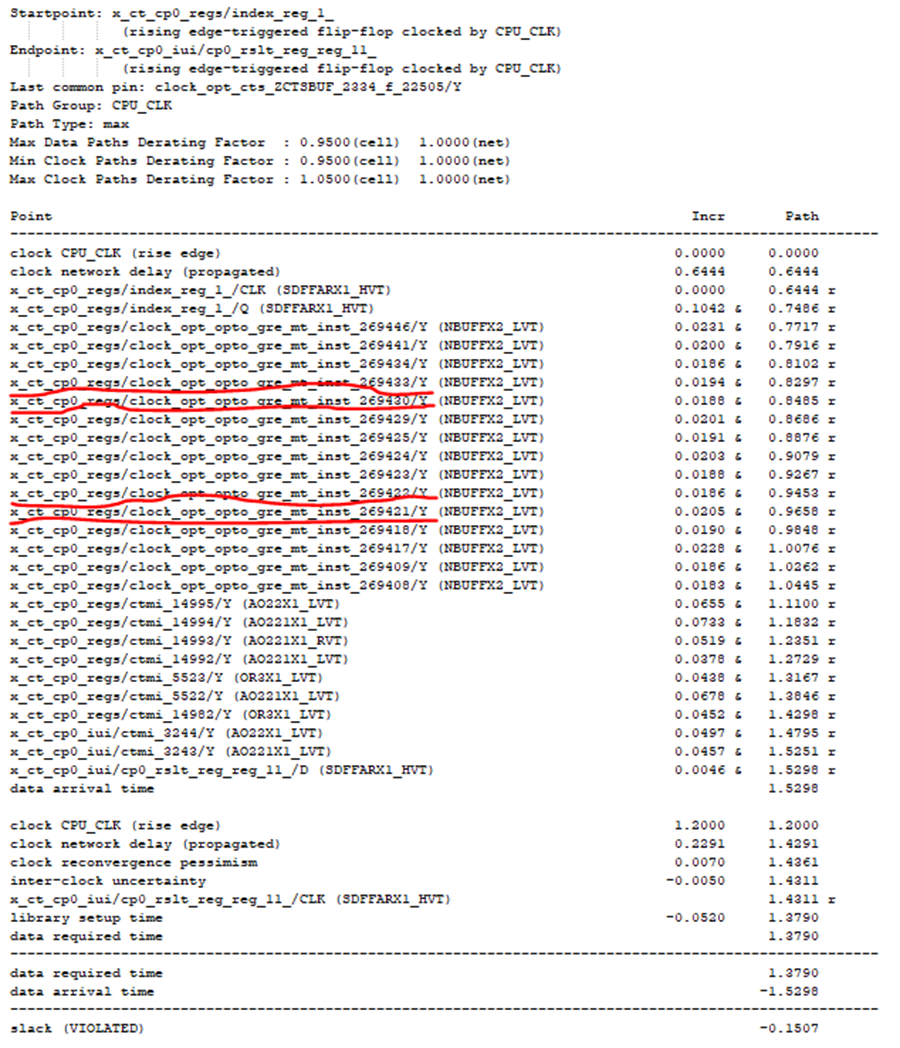
图4
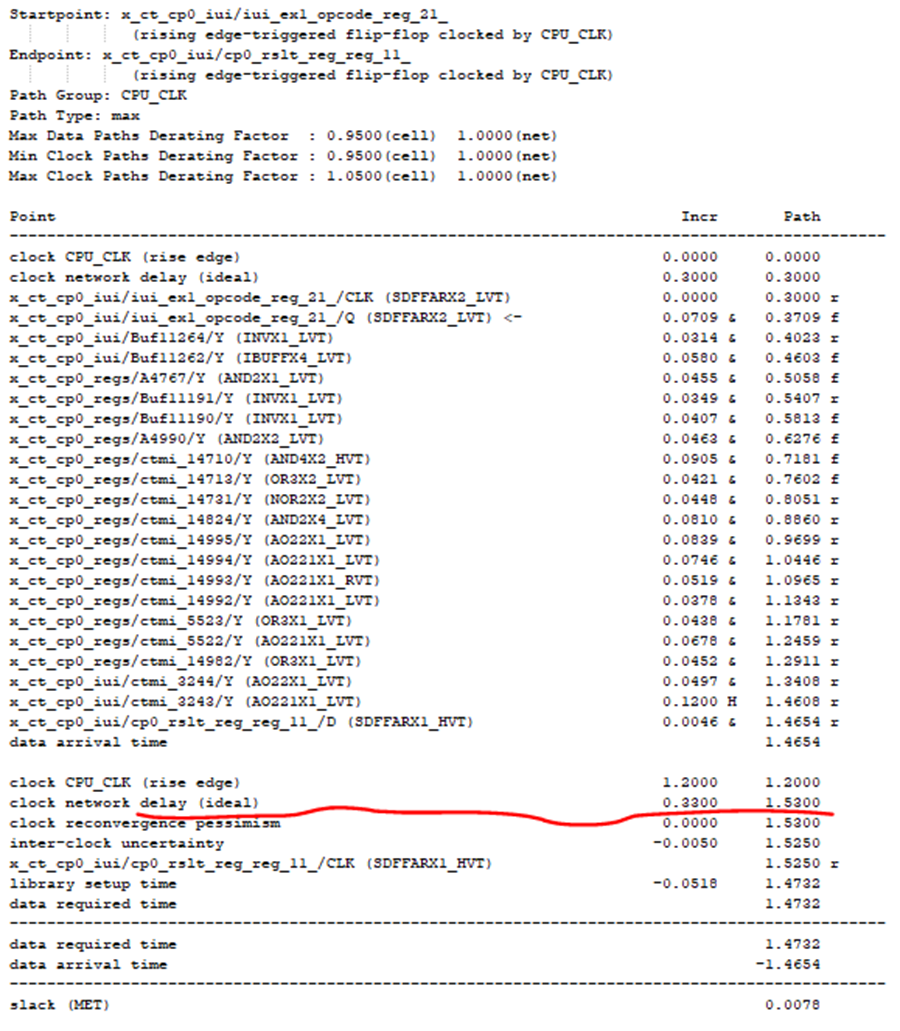
3. 时钟延迟的借用:每一个逻辑路径,最大可以往前2级或后2级通过时钟延迟的推移(借用的办法)来提升设计频率;但时钟的最大借用值不能超过时钟周期的一半。时钟延迟只能在目前时钟延迟的现有值上调整,并假定相关时钟调整只影响该路径下的launch FF寄存器或capture FF寄存器的时钟延迟,不影响其它时序。例子:如下图5所示,时序路径违例-0.0222。在逻辑路径(data path)无法进一步有效优化的情况下,可以考虑把launch时钟延迟减小或把capture时钟延迟增长。假设该例子launch时钟延迟减小会造成前序相关的时序路径产生新的违例,而capture端的时钟延迟增长并没有造成后序的相关时序路径产生新的违例。此时我们选择后者(即通过set_clock_latency增长capture端的时钟延迟)。此优化后,新的时序如图6所示。设计从原违例-0.0222提升为正的0.0078。
图5
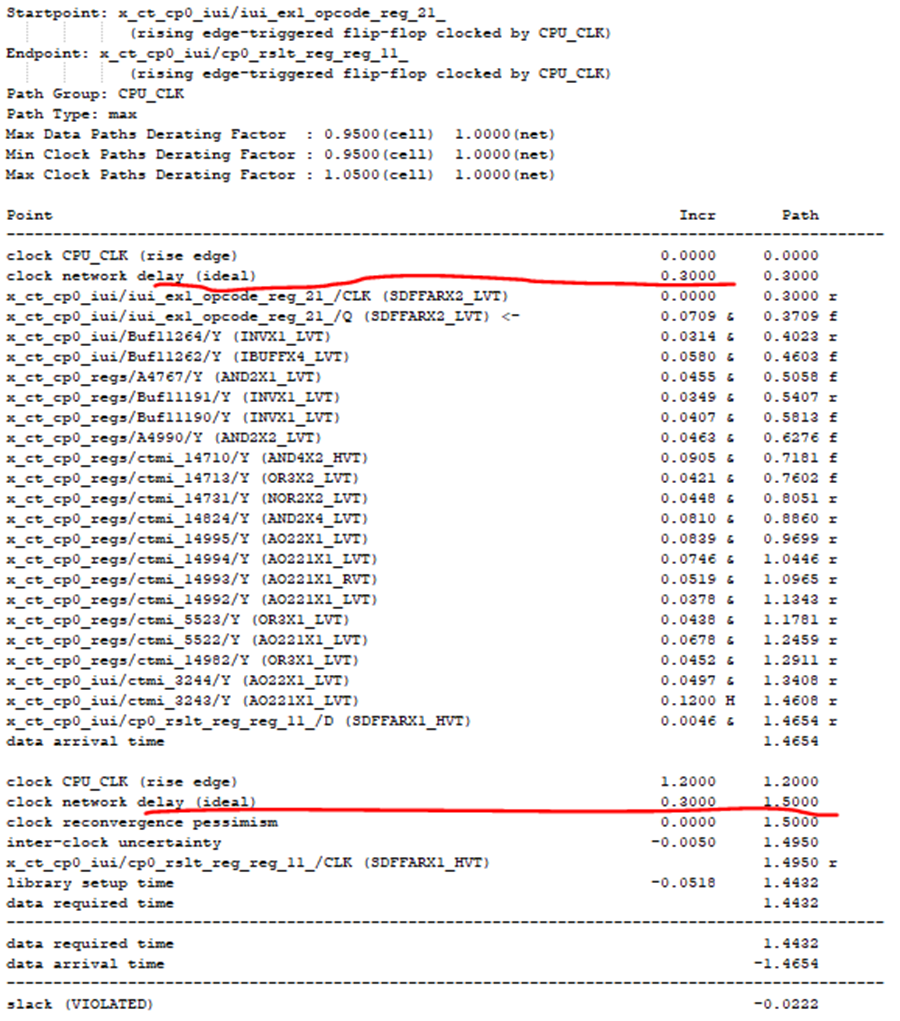
图6
为了避免产生过多的分歧,参赛者需要上面1,2,3顺序进行时序优化分析。参赛者可以在PT里通过tcl脚本完成所有的分析;也可以通过PT产生文本报告,再借助perl/python程序进行分析处理。本分析部分需要产生真实的前10关键路径,此10个路径需要每个路径的launch和capture的FF寄存器和另外的9个路径都不相同。
第二部分:虚拟timing ECO
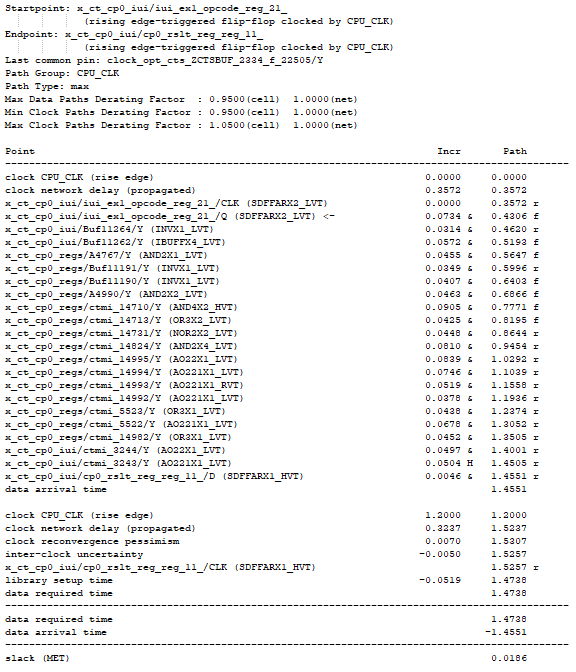
本部分所用数据为已完成完整布局布线(placement&routing)的结果,带有完整的时钟数。参赛者根据第一部分的分析脚本或小软件,模拟P&R实现工程师在timing ECO阶段所作的ECO操作,参赛者需要在PT环境下读入本赛题数据,进行时序分析,找出可被优化的时序违例路径,并判断通过虚拟ECO操作后可时序的最高频率。考虑时间和背景限制,具体可实现ECO限定为和第一部分一样的3类时序可优化情况,即假违例、冗余buffer或inverter和时钟延迟的借用。和第一部分不同的是,所用数据时钟延迟为真实延迟(non ideal), 所以其中时钟延迟只能在目前时钟延迟的现有值上通过ECO(如size_cell, insert_buffer, remove_buffer等)调整。例子:如下图7所示,时序路径违例-0.0518。通过分析,launch时钟延迟为0.3572,capture时钟延迟为0.2533。在逻辑路径(data path) 无法进一步有效优化的情况下,可以考虑把launch时钟延迟减小或把capture时钟延迟增长。假设该例子launch时钟延迟减小会造成前序相关的时序路径产生新的违例,而capture端的时钟延迟增长并没有造成后序的相关时序路径产生新的违例。此时我们选择后者(即通过insert_buffer增长capture端的时钟延迟)。此优化后,新的时序如图8所示。设计从原违例-0.0518提升为正的0.0186。
参赛者在第一部分的的脚本(或软件)基础上,增加代码自动产生ECO操作的所需的PT TCL脚本,ECO操作需按上述1,2,3顺序进行时序优化。自动产生出来的脚本需要在PT里执行无错,并在执行虚拟ECO后用提供的gen_rpt.tcl报出新的时序总结报告。
图7
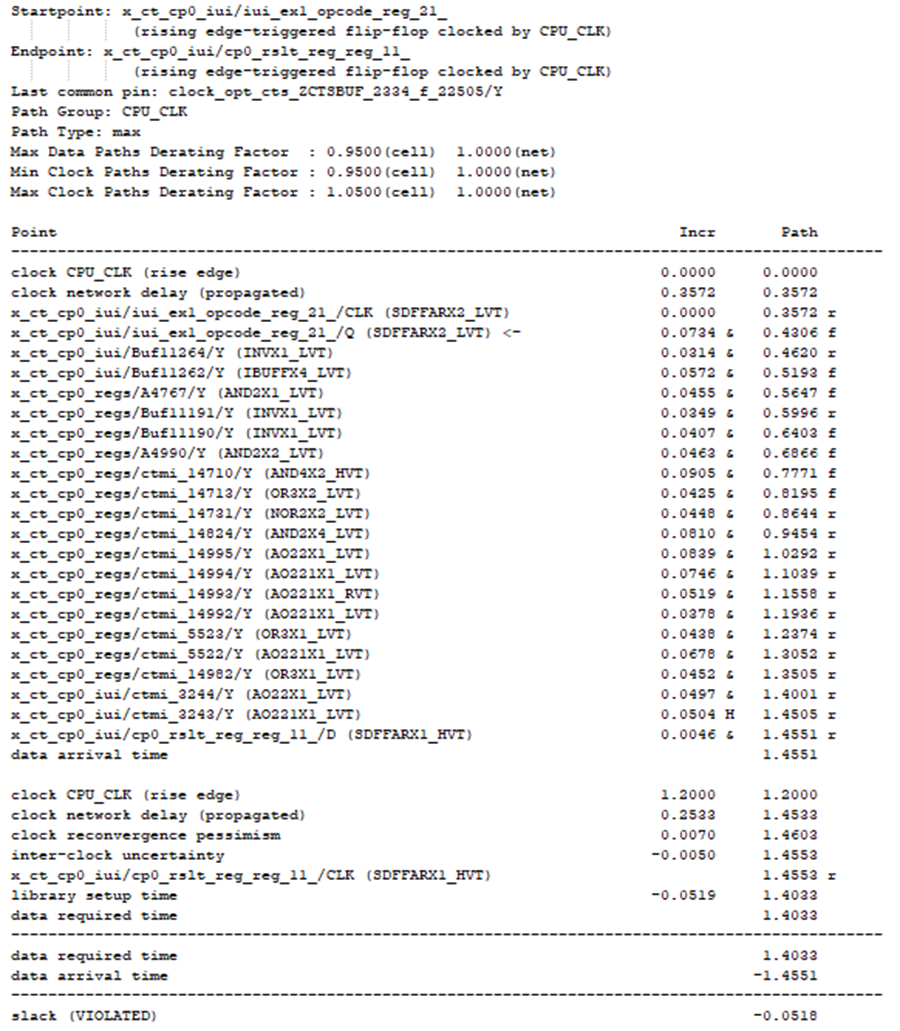
图8
评分标准与奖项设置
赛题作品由虚拟ECO的结果和设计瓶颈分析结果分两步加计评分构成。
虚拟ECO结果部分评分细则:
设计瓶颈分析部分评分细则:
奖项设置:一等奖1名,奖金人民币10000元;
二等奖3名,奖金各人民币5000元.
作品提交要求
涉及软件
(以及相应用户手册)
(以及相应用户手册)
数据包
报名参赛者可发送数据包申请邮件至 snps_cpicic22@synopsys.com
申请邮件请遵循如下格式:
邮件主题:“2022创芯大赛新思科技命题数据包申请_XX大学”
邮件正文请列明以下信息:
申请者:
申请者单位:(学院、专业、年级)
联系电话:
参赛队员:
指导老师:
命题类似项目/学习课程过往经历:(250字左右简要说明)
