

















主题赛事
返回
长川科技企业命题-第九届中国研究生创“芯”大赛
发布时间:2026-03-03
来源:中国研究生创“芯”大赛
阅读次数:5380
关于长川科技
杭州长川科技股份有限公司成立于2008年4月,是一家致力于提升集成电路专用装备技术水平、积极推动集成电路装备业升级的高新技术企业。公司于2017年4月17日在深交所创业板挂牌上市(股票代码300604)。
长川科技总部坐落于杭州市滨江区创智街500号。目前,公司员工超4500人,研发人员占比55%以上,在日本、上海、北京、成都、哈尔滨、苏州、内江、长沙、合肥等地设有分支机构,并先后并购新加坡AOI设备制造商STI、日本SATO公司半导体事业部和马来西亚测试设备制造商EXIS。在深耕中国大陆、台湾地区市场的同时,公司海外市场已开拓至美国、英国、德国、韩国、新加坡,马来西亚、泰国、菲律宾等国家,逐步形成全球化布局。
长川科技一直致力于自主研发。目前已拥有海内外授权专利超1400项,其中发明专利超430项,构筑了严密的知识产权保护体系。公司先后被认定为高新技术企业、国家知识产权优势企业、工信部“单项冠军”企业、杭州市鲲鹏企业等。
作为集成电路测试装备领域的系统解决方案提供商,公司主营产品包括测试机、分选机、探针台、AOI设备,行业深耕多年,技术水平领先,备受行业认可。目前,公司产品已在汽车电子、5G通信、云计算等领域的芯片检测中广泛应用。
长川科技企业命题专项奖说明
长川科技企业命题专项奖专门用于奖励选择长川科技企业命题的赛队,长川科技企业命题专项奖是初赛奖,由企业专家评出。入围决赛的参赛队伍继续参加大赛决赛奖项评比,与初赛长川科技企业命题专项奖互不冲突。
长川科技企业命题专项奖设置
· 特等奖 1队,每队奖金5万元
· 一等奖 4队,每队奖金1万元
· 二等奖 8队,每队奖金0.5万元
长川科技-创芯大赛人才招聘政策
长川科技鼓励从创芯大赛获奖学生中挖掘人才,并在招聘中提供quickpass政策。具体为:
· 获全国一等奖及以上学生,可直接录用;
· 获全国二等奖、三等奖学生,免HR和技术专业面试,直接进入综合面试;
· 长川科技专项奖等级同全国奖对应等级待遇。
组队报名及作品提交链接(创芯大赛官网)赛题目录
https://cpipc.acge.org.cn/cw/hp/10
赛题清单
| 赛题一 | 高分辨率CMOS图像的异构算法设计 |
| 赛题二 | 高精度AWG或DGT的THD校准算法设计 |
| 赛题三 | 大翘曲晶圆吸附仿真与吸盘设计优化 |
| 赛题四 | 跨尺度芯片图像的裂纹缺陷智能检测算法设计 |
赛题一:高分辨率CMOS图像的异构算法设计
背景介绍:
- CMOS 图像传感器是一种将感光和处理电路集成在单个芯片上的图像捕捉器件,应用范围极广,已深入消费电子、工业生产及科技创新的核心领域;图像传感器的测试是通过传感器采集图像数据,对数据进行算法处理,判断图像的像素缺陷及均匀性等参数,进而判断传感器好坏。
- 图像数据分析主要聚焦于两大核心检查项:
- 像素缺陷检查,需在更高分辨率的图像下精准识别并定位亮点、暗点及坏点,确保像素级的良率;
- 噪声及均匀性分析,旨在评估传感器在不同光照条件下的信号纯净度与响应一致性,保障最终成像质量;
描述及要求:
任务前提:所有图像处理基于校正后数据,校正数据请参考calib_params.bin(文件格式说明详见配置文件格式说明.html),校正公式以及暗点,亮点等判定公式详见任务公式.html
核心任务:开发跨平台引擎(C++17 + CUDA/OpenCL可选),对每路CIS传感器RAW数据执行:
任务1:像素级缺陷检测
|
参数 |
算法要求 |
异构建议优化方向 |
|
暗点/亮点 |
局部自适应阈值(5×5邻域) |
GPU并行邻域统计 |
|
坏点定位 |
亮场响应偏离度分析,多帧时序分析(10帧) |
CUDA核函数:每像素独立判定 |
任务2:噪声与均匀性分析
|
参数 |
算法要求 |
异构建议优化方向 |
|
时域噪声 |
10帧标准差计算 |
GPU帧间差分 + CPU全局聚合 |
|
均匀性 |
9宫格ROI对比分析 |
CPU管理ROI坐标,GPU计算区域均值 |
输入/输出规范
输入数据
|
类型 |
规格 |
说明 |
|
图像数据(50MP) |
N×10帧 × 16bit RAW |
均匀光源(5000K),N取1,4 |
|
配置文件 |
test_config.json |
分辨率/阈值/GPU策略,格式详见配置文件格式说明.html |
|
标定参数 |
calib_params.bin |
用于校正原始图像,格式详见配置文件格式说明.html |
输出报告 (cis_report_W{数据组号}_{时间戳}.json)
详见配置文件格式说明.html
性能硬指标
|
指标 |
单组数据@50MP |
4组数据@50MP |
挑战值 |
|
单次处理耗时 |
≤10秒 |
≤ 20秒 |
4组数据 ≤ 10秒 (+15%) |
|
判定准确率 |
暗点/亮点识别准确率 ≥ 99.5% |
同左 |
误判率 ≤ 0.05% (+5%) |
硬性约束
方案自由:纯CPU / CPU+GPU混合 / 纯GPU(需论证资源合理性)
禁止:
GPU方案中CPU空闲率 > 40%
核心算法调用商业库高级函数(基础算子需自实现)
必须支持:
·GPU负载均衡
·单组数据计算成本<3万(50MP)
评审得分点(总分100分)
|
维度 |
占比 |
关键细则 |
|
功能正确性 |
30% |
暗点/亮点准确率≥99.5%; 噪声/均匀性准确率=100%; |
|
异构计算优化 |
30% |
GPU利用率(每+5% +3分);PCIe传输占比<15%; 双GPU吞吐提升≥1.7倍 |
|
产线实用性 |
30% |
硬件成本;计算时间; |
|
工程规范 |
10% |
模块化解耦;Docker Compose一键部署 |
交付物
- 核心代码
- src/cpu/:CPU算法模块
- src/gpu/(若使用GPU):CUDA核函数 + 内存管理
- src/hybrid/:负载调度
- CMakeLists.txt(支持-DUSE_GPU=ON/OFF)
- 设计文档
- 《异构架构设计说明书》
包含总体架构视图, 核心组件与数据流, 计算单元详细设计, GPU/CPU任务调度器设计,以及硬件成本说明
- 验证材料
- GPU/CPU内存利用率监控截图
- json输出报告
- 部署包
- docker-compose.yml
专家答疑邮箱:
yangzhaohui@hzcctech.net
赛题数据集下载(更新于5月2日)
赛题二:高精度AWG或DGT的THD校准算法设计
背景介绍:
1. 在现代测试与测量系统中,任意波形发生器(AWG)和数字采集器(DGT)作为信号生成与采集的核心功能单元,分别依赖于高精度DAC、ADC及运算放大器等关键模拟器件,如图1所示。然而,这些器件本身存在非线性失真,最终会导致系统的指标恶化,对于单音信号,具体表现为THD指标恶化。

图1 AWG与DGT信号链路
2. 现有THD校准技术可分为传统信号补偿方法与新兴数据驱动方法。传统方法通常依赖于对谐波频谱的先验分析,通过生成反相位信号实现抵消,该方案要求对谐波的幅度和相位精准测量,且谐波本身是稳定的,稍有偏差会,校准效果会受影响。近年来,深度学习方法尝试通过神经网络(如LSTM、Transformer)直接学习系统非线性映射,实现端到端校准,此类方法在特定场景下展现出较强的非线性建模能力,减少了对硬件先验知识的依赖。但是,如何在提升补偿精度的同时保障模型的稳定性、可解释性与部署效率,仍是当前研究与工程应用中的关键挑战。
3. AWG和DGT THD校准中的关键指标
在任意波形发生器(AWG)与数字采集器(DGT)的THD校准中,以下三项指标被广泛用于评估系统对非理想信号成分的抑制能力,分别反映噪声、非谐波杂散及谐波失真的校准效果。
① 信噪比(Signal-to-Noise Ratio,SNR)用于表征信号的基波功率与所有噪声总功率的比值(不包含谐波),通常以dB为单位表征。注意THD校准算法不能对SNR指标有恶化。
②非谐波无杂散动态范围(Non-harmonic Spurious-Free Dynamic Range,非谐波 SFDR)用于表征信号的基波功率与扣除谐波成分(包含混叠进Fs/2带内的谐波)后最大杂散信号功率的比值,衡量设备对非谐波杂散干扰的抑制能力,通常以dBc为单位表征。非谐波杂散信号是导致非谐波SFDR指标恶化的最主要原因,注意THD校准算法不能对SFDR指标有恶化。
③总谐波失真(Total Harmonic Distortion,THD)用于表征信号中谐波成分的总功率与基波信号功率的比值,衡量信号的谐波失真程度,通常以dBc为单位表征。谐波类杂散信号是导致THD指标恶化的最主要原因,THD的值越低,说明THD校准对谐波失真的抑制效果越显著。注:混叠进Fs/2带内的谐波信号纳入考量范围,且谐波成分仅计2、3次谐波。
描述及要求:
- 参赛者需基于给定的 AWG(任意波形发生器)或 DGT(数字采集器)链路(二选一)系统架构及实际测试采集数据,设计一套预失真校准算法,并实现对应的补偿系数生成模块与预失真补偿模块。最终提交RTL、MATLAB模块代码与算法技术分析文档(分为AWG和DGT),完成对AWG与DGT各自路径中非线性谐波成分的建模与抑制。
- 赛题将提供少数频点的实际采集数据集(每个频点有6种档位幅度),包含AWG 板卡实际输出的时域采样数据、DGT 板卡实际采集的时域采样数据。参赛者可自行划分训练(train)与验证(verify)数据子集,建议采用理想正弦激励Asin(2πft) 作为参考信号进行误差建模。对AWG,将理想信号与AWG_trainData对齐,训练THD(谐波)逆模型;对DGT,将理想信号与DGT_trainData对齐,学习前端非线性映射。本赛题不限制所采用的建模方法,无论是基于传统信号处理,还是新兴的数据驱动方法,均可自由设计与实现。
- 训练完成后,使用赛题中AWG或DGT采集的数据分类剩下的“AWG_verifyData、DGT_verifyData”进行补偿效果测试,以补偿前后的THD指标收益衡量补偿效果。如图2所示,AWG的补偿效果测试方式为:AWG发出的激励信号经如下路径、高通滤波器(HPF)至频谱仪观测基波信号功率、谐波功率。HPF对基波及2、3次谐波衰减已知,根据上述功率计算对应THD指标;
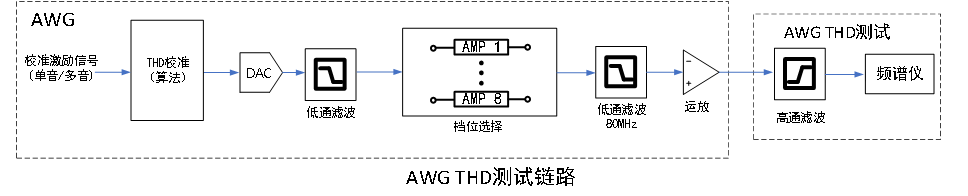
图2 AWG THD测试链路
如图3所示,DGT的补偿效果测试方式为:DGT使用信源经如下路径、低通滤波器(LPF)至DGT获取到目标数据,从而计算动态性能指标THD。
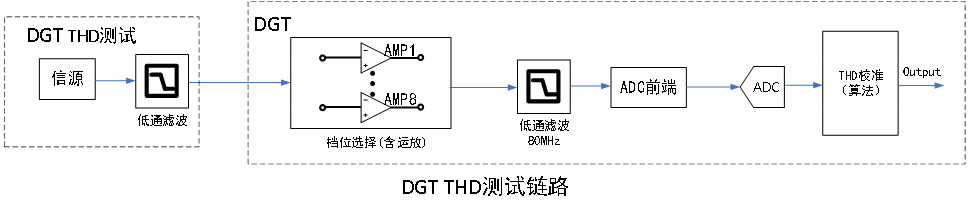
图3 DGT杂散功率测试链路
4.在赛题中给定ADC/DAC采样率和输入、输出数据信号位宽,完成算法方案设计和RTL、MATLAB模块实现;
5.RTL设计需要综合考虑性能和逻辑资源消耗,测试数据完成校准和补偿后的THD需要满足性能指标要求。
6.实际测试抓取的数据下载链接(访问密码:20260316)数据更新于4月24日
https://fex.hzcctech.com:8012/outpublish.html?code=A51ad929eab2d4a899073e0843c096ebf
评审得分点:
1.算法设计与技术分析(占比20%):
所设计的算法必须功能正确,且完全符合题目要求。提交的算法文档须包含完整、详尽的技术分析,包括设计思路、理论推导、关键步骤说明及可行性论证。若算法未实现性能提升,则该文档视为无效。
2. 代码实现与可复现性(占比20%):
提交的算法代码及仿真结果必须具备良好的可复现性。必须提供完整的 MATLAB仿真代码(占比20%)和RTL硬件实现代码(占比10%)。所有代码需能独立运行并生成所述结果。若未实现性能提升,提交的代码将被视为无效,本项得分为零。
3. THD性能指标提升(占比40%):
性能优化效果是核心评价标准,校准算法首先必须实现信噪比(SNR)、SFDR指标不被劣化,且在传输带宽(80MHz)内任意频点、6种幅度档位内THD指标有显著改善,否则整体算法视为无效,文档与代码均不予计分。具体评分标准如下:
THD改善程度,以所提供的数据为参考,THD(包含2、3次谐波)需实现以下改善档位:提升≥1dBc,基础达标;提升≥3dBc,中等提升;提升≥6dBc,良好提升;提升≥10dBc,优秀提升;若改善小于1dBc,性能得分为零,且整个方案视为无效。
4.校准时间与占用资源(占比20%):
本项评估算法在实际部署中的计算效率与校准收敛速度,重点考察其硬件友好性和实时性能力。具体评分标准如下:
4.1 校准时间(占10%):指从启动校准流程到获取最终校准参数所消耗的总时长。若算法涉及自适应校准或迭代优化过程,需明确给出校准所需的迭代次数或时间开销,并与基准方法对比。要求在保证性能提升的前提下,校准过程快速稳定,适用于动态工作场景。
4.2 占用资源(占10%):算法应具备较低的计算复杂度和资源开销,适合在嵌入式或FPGA平台高效实现。需在第一项技术文档中分析运算量(如乘法/加法次数、内存占用等),给出LUT、ffs、BRAM、DSP占用情况,并说明优化策略(如流水线设计、并行处理等)。RTL代码应体现合理的时序性能与资源利用率。
输出要求:
- 算法分析报告(包含方案选择分析、性能结果数据);
- 算法定点化实现文档,仿真代码和仿真结果数据;
- THD_CALI与THD_COMP模块详细设计文档和RTL代码、MATLAB代码,详设文档需说明针对面积功耗所采取的优化措施和取得的结果,此外还需提供测试数据补偿后的指标改善结果、THD校准训练时间、以及补偿系数计算需要的逻辑资源;
- THD_CALI与THD _COMP模块验证环境、验证用例、验证报告;
- 提供IP的性能、面积、功耗评估数据,使用工艺库评估需标明工艺库,RTL代码中涉及的存储单元可以根据需要自行调用对应工艺库的RAM库;
专家答疑邮箱
赛题三:大翘曲晶圆吸附仿真与吸盘设计优化
背景介绍:
在芯片堆叠(Chiplet)等先进封装领域,随着芯片集成度的不断提高和“后摩尔时代”技术路径的演进,晶圆正朝着更大尺寸、更薄厚度和更复杂多层结构的方向发展。特别是以芯粒为代表的异构集成技术(Heterogeneous Integration),将不同工艺、不同功能的芯片裸片(Die)通过先进封装技术进行堆叠与互连,这进一步加剧了晶圆结构的非均匀性与三维复杂性。这一趋势导致晶圆在制造过程中的热-机械应力失配问题愈发突出,从而产生显著的翘曲(Warpage),翘曲量通常可达毫米级别。
探针台(Prober)是芯片电性测试的核心设备,其通过精密真空吸盘(Chuck)固定晶圆,并驱动探针卡(Probe Card)上的微型探针与晶圆上每个芯片的焊垫(Pad)或凸块(Bump)进行精准接触,以完成电学参数测试。传统探针台的吸盘与测试算法基于“理想刚性平面晶圆”的假设,其吸附策略、对位系统和接触力控制均针对平坦或微翘曲晶圆优化。当面对大翘曲晶圆时,探针台在测试环节将面临严峻挑战:晶圆表面高度的剧烈变化导致探针接触失效;翘曲使基于机器视觉的自动对位系统出现误判,聚焦偏差和坐标提取错误导致探针偏离焊盘;接触压力不均引起接触电阻大幅波动,破坏高频或大电流测试的信号完整性。
因此,开发能够自适应大翘曲晶圆的新一代智能真空吸盘及其控制策略,已成为提升先进芯片测试能力的关键。而解决此难题的首要步骤,是建立能够精准预测吸附过程中力学行为的仿真模型,即一个高保真的流固耦合(Fluid-Structure Interaction, FSI)瞬态动力学仿真模型。该模型可以准确描述吸附过程中的大变形行为、晶圆与吸盘的接触非线性,以及气隙流程与结构变形的双向耦合作用,为后续优化吸盘结构(如分区气压控制、柔性界面设计)和制定智能测试序列的制定提供基础。本赛题旨在引导参赛者攻克上述仿真难题,为后续面向测试应用的吸盘创新设计与智能测试策略奠定坚实的数字孪生基础。
描述及要求
任务:翘曲晶圆真空吸附瞬态动力学仿真模型开发
1.物理过程与仿真目标
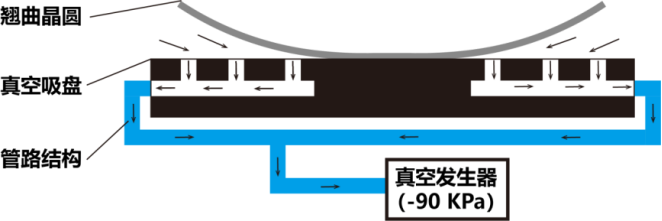
图4 翘曲晶圆真空吸附瞬态动力学仿真模型示意图
真空吸盘吸附对象是12寸的翘曲晶圆,初始状态下晶圆呈现给定的翘曲形态(例如中间凸起的“哭脸”或中间凹陷的“笑脸”),翘曲量≤3 mm。如图4中典型案例所示,“笑脸”晶圆悬置于真空吸盘上方,两者之间存在不均匀的气隙。当真空发生器开启后,其控点传感器记录的压力迅速降至设定值(如-90 kPa),压力变化通过管路结构传递至吸盘内部的气孔和沟槽。在上下表面压力差的作用下,晶圆开始发生弹性变形,逐步向吸盘表面贴合。最终,晶圆与吸盘达到力学平衡,晶圆被稳定吸附在吸盘上,接触压力分布、晶圆内部应力分布以及晶圆形态趋于稳定,整个吸附过程的时间尺度约为100毫秒(图5)。
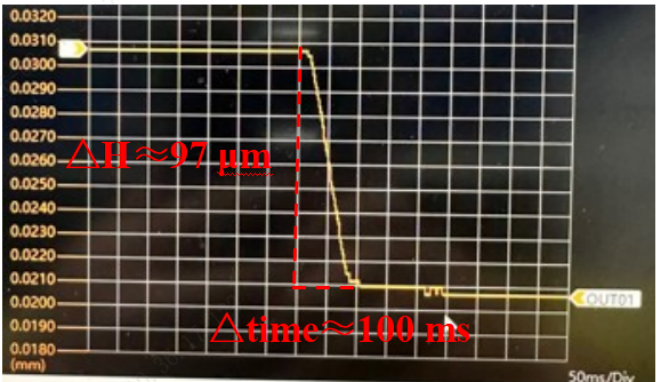
图5 “笑脸”翘曲晶圆边缘上一点的运动曲线
仿真目标是构建一个高保真的瞬态仿真模型,能够复现上述物理过程,并准确预测以下关键输出:吸附过程中晶圆变形随时间演变的动画;晶圆与吸盘之间接触压力分布的时空演化;晶圆内部的应力分布,识别最大应力位置和数值;达到稳定吸附状态所需的时间;以及吸附稳健性指标,如接触面积比、最大应力是否超过材料屈服强度等。
2.建模方法(供参考)
- 流体域
经过初步仿真计算,初始时刻吸盘气孔处最大流速大约有300 m/s,因此需要考虑空气的可压缩性。
- 固体域
晶圆视为线弹性薄板,在压力载荷下产生非线性大变形。
- 流固耦合界面条件
流体压力与粘性应力作为面力施加与晶圆表面:
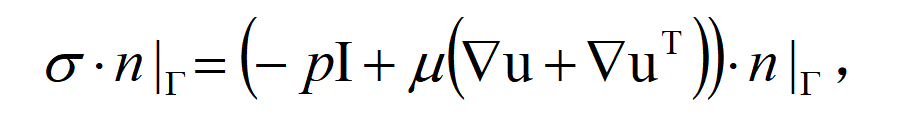
n为界面法向单位矢量。
运动的连续性条件为:
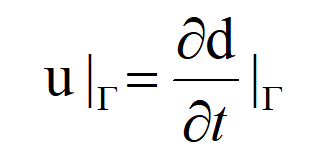
- 流体域与固体域网格划分
推荐采用动网格/ALE方法描述流固界面变形;ALE方法核心是引入任意拉格朗日–欧拉坐标系,通过坐标变换关联流体运动与网格变形,其数学表达为坐标变换方程:
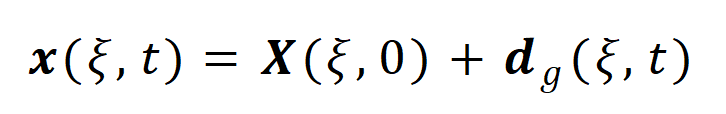
式中:![]() 为 ALE坐标系下网格节点的瞬时位置矢量,
为 ALE坐标系下网格节点的瞬时位置矢量,
![]() 为初始时刻(t=0)网格节点的拉格朗日位置矢量,
为初始时刻(t=0)网格节点的拉格朗日位置矢量,
![]() 为网格节点的物质坐标(固定不变),
为网格节点的物质坐标(固定不变),
![]() 网格节点的瞬时位移矢量。考虑到吸附过程中晶圆与吸盘之间的间隙会逐渐缩小至零,需重点设置网格自适应变形策略,避免网格畸变导致仿真收敛失败。
网格节点的瞬时位移矢量。考虑到吸附过程中晶圆与吸盘之间的间隙会逐渐缩小至零,需重点设置网格自适应变形策略,避免网格畸变导致仿真收敛失败。
3.已知结构与边界条件
主办方将提供以下输入数据与模型,供参赛者建立和校准仿真:
·多种翘曲形态的晶圆几何模型(如“笑脸”和“哭脸”形变),并给出相应翘曲量的三维坐标数据或数学描述;
·晶圆材料参数(仅供参考,以附件为准):
|
弹性模量(E) |
泊松比(ν) |
密度(ρ) |
弯曲强度 |
热膨胀系数(CTE) |
比热容(Cp) |
热导率(k) |
|
25GPa |
0.22 |
2.1g/cm³ |
120MPa |
18ppm/°C |
1.4J/(g·K) |
1.2W/(m·K) |
·吸盘几何参数(仅供参考,以附件为准):
|
总直径 |
总厚度 |
吸附直径 |
保留宽度 |
气孔总数量 |
槽口宽度 |
|
305mm |
12mm |
278.8mm |
13.1mm |
135个 |
0.8mm |
|
8寸吸附区 |
12寸吸附区 |
||||
|
气孔深度 |
气孔直径 |
真空发生器 |
气孔深度 |
气孔直径 |
真空发生器 |
|
33mm |
0.8mm |
独立 |
44.65mm |
33mm |
独立 |
·晶圆吸附气体流动示意图:
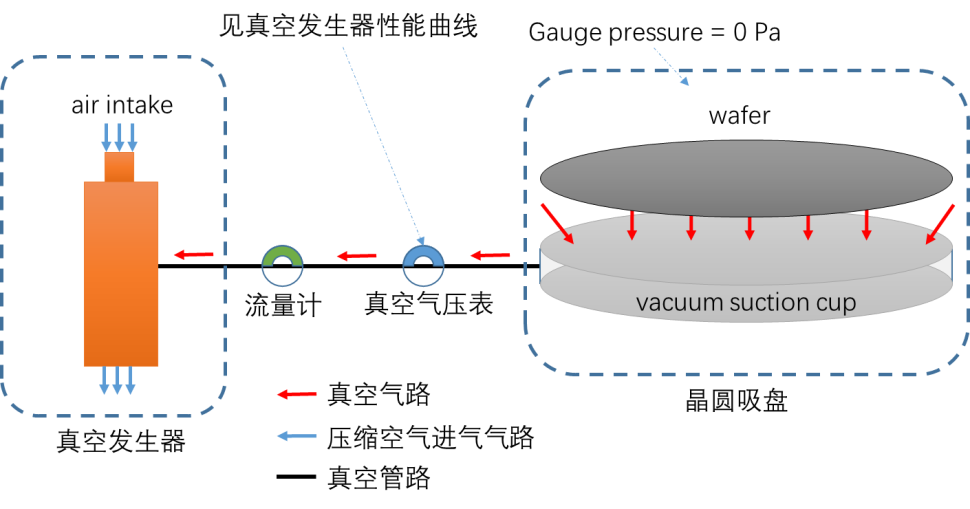
图6 晶圆吸附气体流动示意图
·吸附流程:
|
阶段1 |
|
|
阶段2 |
|
·真空发生器不同真空度下流量:
|
真空度 |
kPa |
0 |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
|
真空流量 |
Nl/s |
16.8 |
7.5 |
5.4 |
3.3 |
1.95 |
1.5 |
1.05 |
0.75 |
0.3 |
0 |
·真空发生器不同真空度下抽真空时间:
|
真空度 |
kPa |
10 |
20 |
30 |
40 |
50 |
60 |
70 |
80 |
90 |
|
抽真空时间 |
s/L |
0.007 |
0.02 |
0.04 |
0.08 |
0.15 |
0.23 |
0.33 |
0.53 |
1.33 |
在实际模型中,真空发生器直接连接真空吸盘,不用考虑流量计对系统流动的影响,但需要考虑真空气管的影响(见附件的三维模型)。
·用于校准的实测曲线
实测校准数据针对其中一种翘曲形态的晶圆,主办方将提供完整的实验测试数据,包括晶圆边缘指定点的垂向位移随时间变化曲线。预测验证数据主办方将提供另外3~5种不同翘曲形态的晶圆几何模型及相应的边界条件,但不提供其实测结果。
评审得分点
| 序号 | 评审项目 | 要求 | 说明 |
| 1 | 仿真结果准确性(50分) | 考虑空气可压缩性,定义晶圆与吸盘间的摩擦接触,处理晶圆大变形几何非线性。 | 在当前型号真空发生器参数下,不同晶圆 (5种)仿真结果定性正确: 5片趋势一致 20分 4片趋势一致 15分 3片趋势一致 10分 其它 0分 |
| 以A晶圆为研究对象,定量研究吸附最小真空度最小误差: <5% 30分 <10% 20分 <20% 10分 其他 0分 |
|||
| 2 | 仿真效率 (30分) |
参考算力: CPU:56核 内存通道数:16 不允许GPU加速 单算例定义:从获取完整仿真输入信息到仿真计算出结果(仿真全流程) |
完成单算例耗时: <6小时/case 30分 <24小时/case 20分 <72小时/case 10分 >72小时/case 0分 |
| 3 | 模型通用性(20分) | 1、参数化适应性:模型是否支持参数化输入(如尺寸、材料、载荷)并能快速重运行 2、工况覆盖范围:模型能否适用于多种工作条件 3、几何兼容性:是否适用于不同几何构型 4、材料可扩展性:是否支持多种材料 |
四项评分标准每满足一项加5分 |
输出要求
- 综合技术报告(PDF格式):
详细描述一项任务的完整方案、实施步骤、所有结果与分析。包含方法原理图、仿真设置截图、结果曲线图(如位移-时间曲线、应力分布云图)、数据表格等。包含“模型验证与误差分析”专门章节。包含团队分工、项目总结与展望。
- 数字模型与数据文件:
完整仿真模型文件(商用软件)、计算程序,以及所有用于仿真的输入数据和处理后的输出数据。
- 仿真结果展示视频(可选但建议):
一段不超过3分钟的短视频,动态展示翘曲晶圆吸附过程的仿真动画,并突出关键结果。
专家答疑邮箱:
赛题四:跨尺度芯片图像的裂纹缺陷智能检测算法设计
背景介绍:
在半导体制造与封装测试环节,芯片表面裂纹(Crack)是导致器件失效的关键缺陷之一,微裂纹引发的早期失效可能导致严重的安全事故。
裂纹的产生通常源于多物理场耦合应力,主要成因包括:
热应力失配(Thermal Mismatch):芯片材料、基板与封装材料的热膨胀系数不一致,在回流焊或温度循环测试中产生剪切应力,导致界面开裂。
机械损伤(Mechanical Stress):晶圆减薄、划片过程中的机械振动,或搬运过程中的微碰撞,易在芯片边缘或应力集中区产生微裂纹。
工艺缺陷(Process Defects):金属层沉积不均、通孔填充空洞等前道工艺问题,在后道封装应力释放下扩展为宏观裂纹。
此外,随着芯片工艺制程的进步及封装形式的多样化,自动光学检测(AOI)设备面临的图像数据呈现出极端的尺度变化特征。一方面,不同检测机台、不同放大倍率下采集的芯片图像分辨率差异巨大;另一方面,裂纹缺陷本身的形态跨度极广,既存在肉眼难以察觉的微细裂纹,也存在贯穿芯片的宏观断裂,如图7所示:
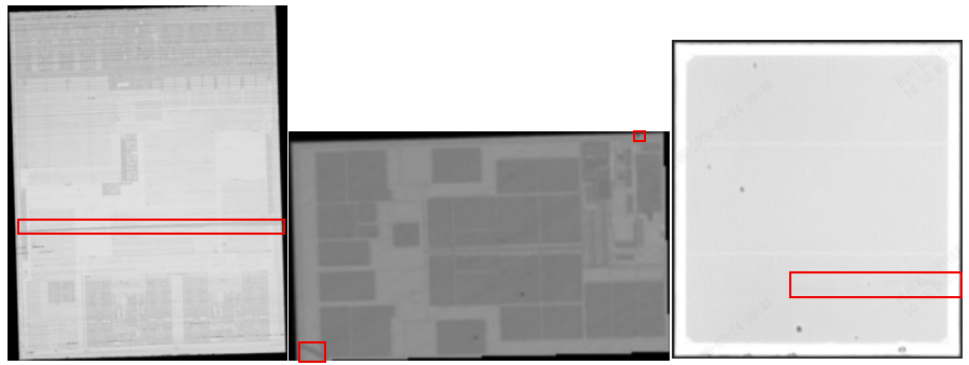

图7 图像数据中多尺度缺陷示意图
传统的深度学习检测模型通常基于固定输入分辨率设计,难以同时兼顾极大分辨率图像中的微小目标检测与极小分辨率图像中的全局上下文理解。当图像分辨率跨度超过百倍、缺陷尺寸跨度超过千倍时,常规的特征金字塔或多尺度训练策略往往失效,导致微小裂纹漏检或宏观裂纹定位不准。
本题目基于真实场景下的极端尺度数据,要求参赛队伍设计具备强泛化能力的智能检测算法,能够同时解决“大图小缺陷”难发现、“小图大缺陷”难定位的行业痛点,提升芯片缺陷检测的准确率与鲁棒性。
描述及要求:
参赛队伍需设计并实现一个能够适应极端尺度变化的芯片裂纹检测算法,具体任务及要求如下:
1.核心任务
构建一个基于可工业落地的AI缺陷检测算法,输入为不同分辨率的芯片图像,输出为裂纹缺陷的位置信息(可选择性构建目标检测或者实例分割算法模型)。算法需在不针对单张图像单独调整超参数的前提下,实现对全尺度范围数据的有效检测。
2.数据尺度约束
算法必须能够处理以下极端尺寸范围的数据,且保证性能稳定:
a.图像尺寸范围(数据集全为单通道的灰度图样本):
- 最小输入图像:59 × 46 像素
- 最大输入图像:7465 × 9263 像素
- 要求:设计的检测算法需兼顾不同的输入图像尺寸,例如设计有效的高效的图像分块或弹性缩放等策略。
b.缺陷尺寸范围:
- 最小缺陷尺寸:1 × 3 像素(微细裂纹)
- 最大缺陷尺寸:3947 × 3703 像素(宏观断裂)
- 要求:需解决极小目标特征消失及极大目标感受野不足的问题。
c.缺陷类型:仅针对 Crack(裂纹)类别进行检测。
3.功能与性能要求
a. 检测精度:
- 总体上需保持较高的检测精度
- 微小缺陷(目标宽度≤5像素或面积≤50像素²)上需保持较高的召回率
- 极大缺陷(目标面积≥300x300像素²)上需保持较高的定位精度
b. 检测跨度能力:模型应自适用于不同分辨率的输入(涵盖59 × 46至7465 × 9263尺度的图像样本)。
c. 推理效率:
- 对于常规尺寸图像(如≤2048×2048),单张推理耗时应<100ms。
- 对于超大尺寸图像(最大尺寸7465×9263),需设计合理的推理或加速机制,单张推理总耗时应 < 2s。
注:推理耗时包含预处理、模型前向传播、后处理全流程,但不包含数据加载时间,后续主办方会统一在英伟达4080显卡上统一校验推理速度。
d. 资源消耗:
- 显存/内存占用需合理,支持在主流 GPU 服务器环境下运行(训练推理时消耗总显存<16G),鼓励进行模型轻量化设计。
评审得分点:
- 检测性能(40%)
- 极小缺陷检测能力(10%):针对所有极小裂纹,召回率(Recall)是核心考核点。若漏检率高,此项得分大幅扣除。
- 极大缺陷定位精度(10%):针对所有极大裂纹,考核平均边界框交并比(mean bbox IoU),要求边界贴合紧密。
- 综合精度(10%):全测试集上的 mAP50排名(实例分割与目标检测均按照bbox mAP来计算)。
- 推理耗时(10%):全测试集上的平均推理耗时。
- 技术方案创新性(30%)
- 跨尺度架构设计(15%):是否提出了新颖的多尺度特征融合机制、动态分辨率策略、注意力机制或切片推理算法来解决尺度跨度问题。
- 小目标增强策略(10%):针对极小缺陷,是否有特殊的损失函数设计、数据增强或超分辨率辅助手段。
- 算法复杂度优化(5%):在保证精度的前提下,是否对计算量进行了有效优化。
- 代码完整性与工程化(20%)
代码规范与复用性(20%):代码结构清晰(包含数据集前后处理、模型算法训练、样本推理及可视化等),接口定义明确,具备良好的代码编写风格。
- 设计报告与答辩(10%)
- 文档质量(5%):技术报告逻辑严密,对极端尺度问题的分析深入,实验对比充分。
- 现场演示(5%):视频或现场演示流畅,能够直观展示算法对大小尺寸图像的处理能力。
输出要求:
- 源代码包:
①需包含完整的数据预处理、模型训练、推理评估脚本。
②提供 requirements.txt 或 Dockerfile 以确保环境可复现。
③代码中需包含关键算法模块的注释。
- 模型权重文件:
提供在验证集上(自行划分)表现最佳的模型参数文件(如 .pth, .onnx 等)。
- 技术设计报告(Word、PDF 格式):
包含方案架构图、解决跨尺度问题的核心思路、优化加速策略、实验数据对比、误差分析及结论。
- 测试结果文件:
按照组委会提供的格式模板,提交对测试集的预测结果以及每张测试集图片的耗时记录文件(JSON格式)以及测试结果推理生成脚本,需要使用2中的权重文件测试结果可以复现。
备注:赛题提供包含上述尺度范围的数据集用于模型的训练与验证。参赛队伍需注意数据隐私,不得将数据集公开传播。
数据集下载链接(访问密码:20260316)数据更新于4月24日:
https://fex.hzcctech.com:8012/outpublish.html?code=Af0fe3fa72bd246d2b7fca2b26d980600
